Principaux modèles de SGBD
Au fil de l'évolution de la technologie et des besoins pour des bases de données, différents modèles de données ont vu le jour. Les modèles présentés sont quelques uns des principaux modèles, mais d'autres existent.
Modèle textuel (fichier plat)
Les données, dans le modèle textuel, sont structurées en une seule table, chaque ligne représente un enregistrement et chaque colonne, un champ. Les enregistrements dans cette table de données ne sont pas reliés entre eux.
Ce type de bases de données propose habituellement des fonctionnalités bien adaptées aux données textuelles, c'est-à-dire composées surtout de phrases ou de mots, comme, p. ex., des opérateurs de proximité.
Inmagic DB/TextWorks est un exemple de base de données basée sur le modèle textuel. Plusieurs bases de données commerciales accessibles en ligne sur des serveurs sont gérées par des SGBD textuels.
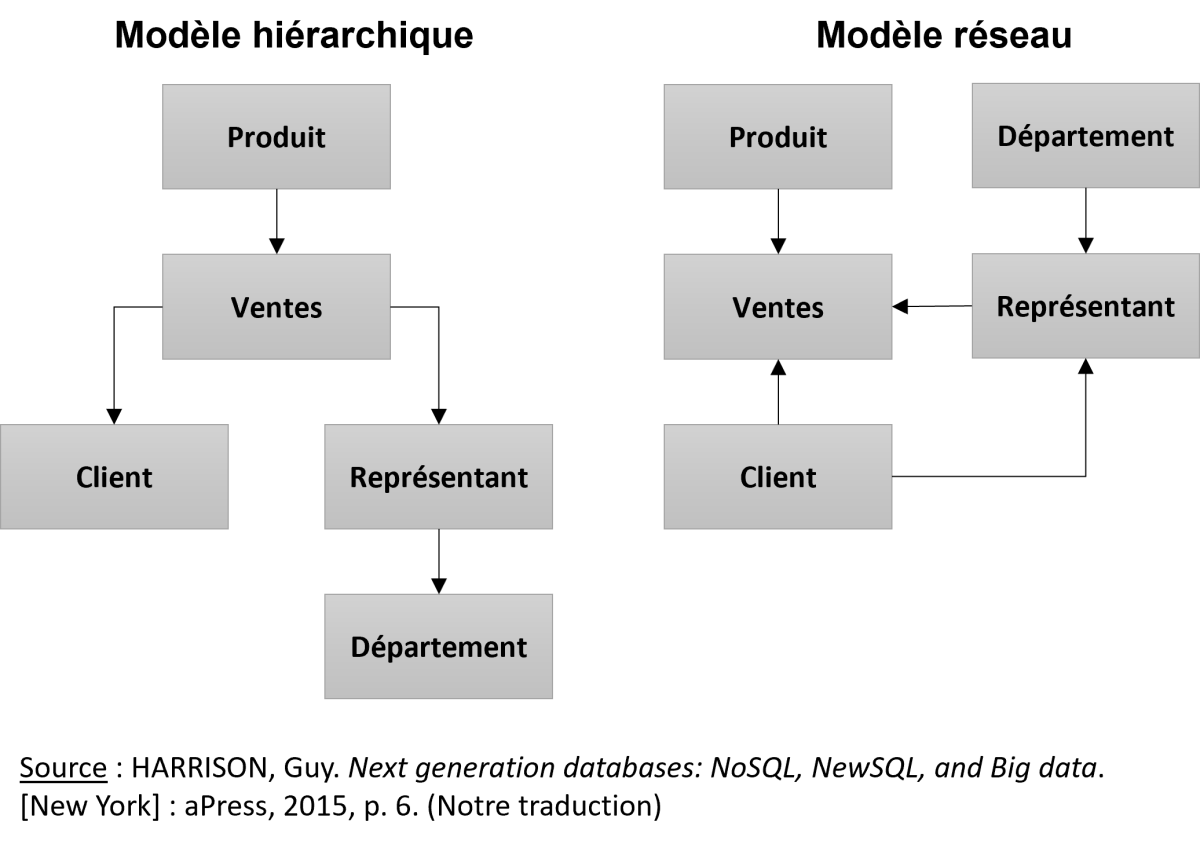
Modèles hiérarchique et réseau
Tant le modèle hiérarchique que le modèle réseau sont aujourd'hui obsolètes. Ils demeurent toutefois des jalons importants dans l'évolution des bases de données, le modèle hiérarchique étant apparu en premier suivi du modèle réseau. Une de leur principale faiblesse est que tous deux présentaient une indépendance limitée des données par rapport aux applications et aux technologies. Ils ont été dépassés par le relationnel à partir des années 1980 (arrêt du développement de nouvelles applications selon ces modèles).
Modèle hiérarchique | Modèle réseau |
|
|
Modèle relationnel (rappel SCI6005)
Défini formellement (mathématiquement) avant toute implantation par l'informaticien britannique Edgar Frank Codd en 1970, ce qui en fait un "vrai" modèle. Le premier produit basé sur ce modèle a vu le jour à la fin des années 70.
Modèle encore le plus utilisé actuellement. Beaucoup de systèmes intégrés de bibliothèques (SIGB) et autres applications documentaires sont construites sur des SGBD relationnels. Aussi très présent au niveau des systèmes d'information Web, quoiqu'il ne soit plus le seul!
Ses limites pour les systèmes distribués à grande échelle sur le Web comme Twitter et Facebook ont conduit à l'apparition des familles de bases de données NoSQL (Not Only SQL)
Pointures de SGBD relationnels
On retrouve des SGBD relationnels de taille variable selon les contextes et les besoins auxquels ils répondent. Dans le cadre du cours, nous explorerons les SGBD relationnels de petite pointure.
Petite pointure = SGBDR personnels | Grande pointure = SGBDR corporatifs |
|
|
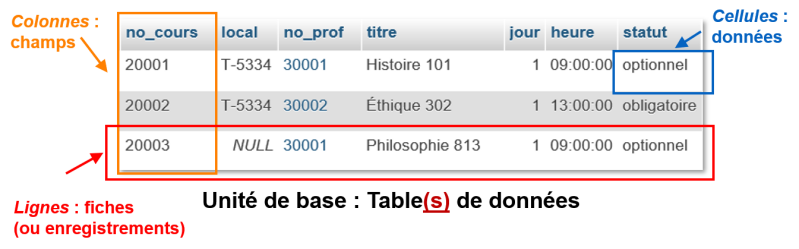
Modèles textuel et relationnel : principales ressemblances
Les SGBD textuel et relationnel se ressemblent quant au contexte global de leur utilisation ainsi que l'unité de base utilisée pour structurer les données.
SGBD textuel Par ex. DB/TextWorks | SGBD relationnel Par ex. Access et MySQL | |
Type de « contenants » d'information | BD créée avec le logiciel | BD créée avec le logiciel |
Recherche de fichiers | non | non |
Recherche de fiches/enregistrements | toujours | toujours |
Structuration en champs | toujours | toujours |
Modèles textuel et relationnel : différences au niveau de la structure
Les modèles textuel et relationnel diffèrent quant au nombre de tables de données qu'elles peuvent utiliser pour structurer une base de données ainsi qu'au nombre d'occurrences que l'on peut retrouver dans un champ.


Modèles textuel et relationnel : différences au niveau de la recherche
En sus des différences et ressemblances entre les deux modèles concernant leur manière de structurer les données, ces derniers se ressemblent sur certains points et diffèrent sur d'autres quant aux opérations de recherche dans une base de données.
Textuel : Db/TextWorks | Relationnel : MySQL | |
|---|---|---|
Recherche indexée | toujours | facultatif (sauf pour la recherche avancée plein texte) |
Visualisation de l'index | oui | non |
Antidictionnaire | un par base, modifiable (applicabilité par champs) | non (sauf pour la recherche avancée en plein texte) |
Autres critères sur les métadonnées | non | non |
Signes diacritiques ignorés | facultatif | facultatif |
Opérateurs booléens | oui | oui |
Troncature | oui | oui |
Opérateurs de distance | oui (dans l'ordre ou non) | non (sauf pour la recherche avancée plein texte) |
Autres opérateurs (p. ex. mathématiques) | limités | oui |
Modèles textuel et relationnel : en résumé
Il est important de connaître les caractéristiques des modèles textuel et relationnel afin de mieux en comprendre l'utilisation et faire des choix plus éclairés vers l'un ou l'autre de ces modèles en fonction du contexte.
SGBD textuel Par ex. DB/TextWorks | SGBD relationnel Par ex. MySQL | |
|---|---|---|
Nombre de table de données | une | une ou plus |
Occurrences multiples dans un champ | oui | non Les occurrences multiples sont recréées, à la demande, par des requêtes reliant des tables |
Possibilité d'avoir 0 occurrence dans un champ | oui | non La valeur NULL est utilisée pour "simuler" l'absence d'occurrence |
Types de données | plus limités | plus riches et plus forts |
Langage d'interrogation | plus limité globalement, mais présente plus d'opérateurs pour les données textuelles | plus riche (SQL) sauf pour certains aspects du traitement des données textuelles qui nécessitent de passer par la recherche avancée plein texte |
Limites du modèle relationnel
Le fait d'avoir mathématiquement et formellement défini le modèle relationnel avant toute implantation lui a permis de "bien vieillir", comme il a ainsi gagné en indépendance par rapport aux technologies.
Ceci dit, l'évolution entre autres du matériel informatique, des langages de programmation, des exigences des interfaces-utilisateurs, des applications multimédia ainsi que de la réseautique en a fait ressortir des limitations, ce qui a amené d'autres modèles à émerger. C'est le cas entre autres des familles NoSQL nées des besoins pour des systèmes distribués à grande échelle comme Twitter ou Facebook.
Familles NoSQL
L'appellation NoSQL (Not only SQL) date de 2009. Le modèle relationnel, dans sa manière de représenter et de manipuler les données du modèle relationnel, se révèle peu efficace dans le contexte d'environnements Web distribués à grande échelle qui possèdent de grands volumes de données (p. ex Twitter, Facebook, eBay).
Les familles NoSQL délaissent les propriétés des transactions relationnelles qui permettent de garantir et de maintenir la cohérence des données (propriétés ACID) au profit de contraintes qui priorisent la disponibilité des données (contraintes BASE).
Il ne s'agit pas d'un modèle NoSQL, mais de plusieurs familles NoSQL qui se sont développées en parallèle et qui répondent à des besoins différents.
Familles | Exemples d'utilisation |
|---|---|
Orientées graphes pour traiter les réseaux massifs | Recommandations Twitter |
Orientés colonnes pour faciliter les traitements privilégiant les colonnes | Calcul de l'âge moyen des utilisateurs |
Orientées clé/valeur pour gagner en efficacité en lecture/écriture et pour le changement d'échelle | Système de sauvegarde de type Dropbox |
Orientée "document" pour supporter des structures variables | Gestion des métadonnées des produits vendus chez eBay |
Ces nouvelles familles de bases de données présentent comme principal avantage de contourner les limites du modèle relationnel contraignantes pour le contexte de systèmes Web distribués à grande échelle (fortes performances, résistance au changement d'échelle, entre autres). Elles ne sont toutefois pas exemptes de limites, par exemple du fait de leur relative jeunesse et du développement en parallèle de plusieurs familles.
Avantages | Désavantages |
|---|---|
|
|
Remarque :
L'information présentée dans cette section provient de S4.4 : Bases de données non relationnelles / Habert[1], que vous pouvez consulter pour plus d'informations sur ces dernières.
Modèle hypertextuel
Le modèle hypertextuel remonte, dans sa conceptualisation, à 1945. Vannevar Bush, dans son texte "As We May Think",[2] propose l'idée d'une machine, nommée MEMEX, pour résoudre les problèmes liés à l'explosion documentaire. Cette dernière serait en effet en mesure de ranger et rendre accessible tous les documents en permettant :
La visualisation des documents sur microfilm sur un écran, documents pouvant être complétées par des images ;
La localisation des documents ;
L'inclusion de pistes associatives entre les documents.

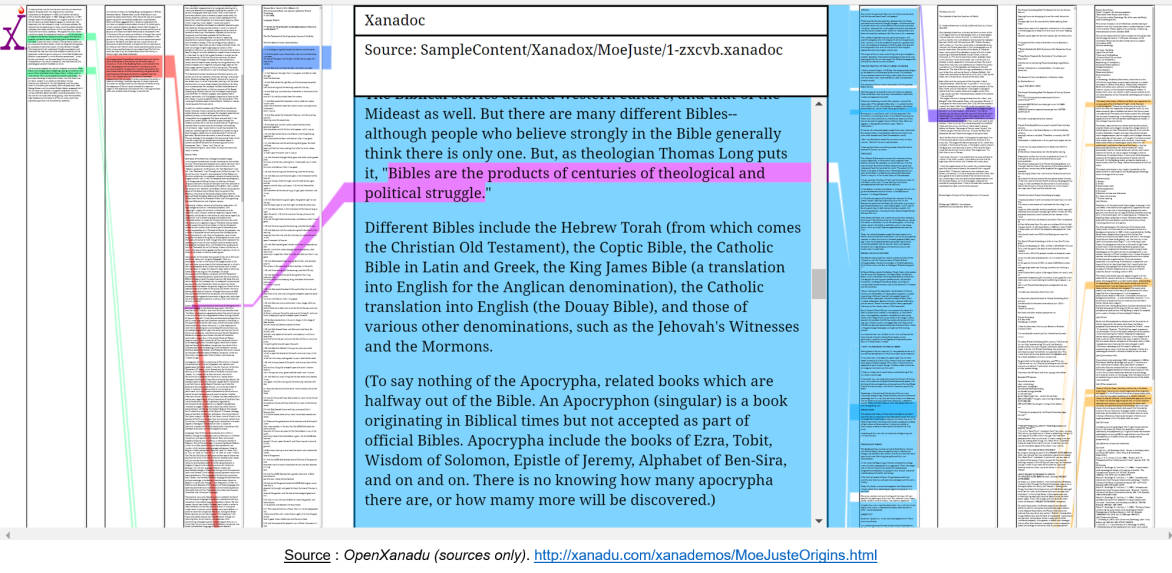
Le néologisme "hypertexte" a été proposé par le philosophe et sociologue américain Theodore Nelson en 1965. Il est à l'origine du projet Xanadu dont l'objectif était de regrouper tous les documents de l'humanité. Ce système, accessible à tous, permettrait l'ajout de documents et la définition de liens entre ces derniers. Au départ, il s'agissait uniquement d'une conceptualisation sans implémentation. Depuis, des démonstrations ont vu le jour après bien des années dont OpenXanadu en 2014[3].
Le premier logiciel hypertexte grand public, créé par Bill Atkinson, est HyperCard (Apple) en 1987, logiciel dont le développement s'est terminé en 1998. Il permettait de présenter des contenus multimédias sur des fiches cartonnées, cartes qui pouvaient être liées entre elles par des boutons. Pour les curieux (ou les nostalgiques!), Internet Archive a mis en ligne en 2017 pour fêter les 30 ans d'HyperCard une collection de projets HyperCard.

L'application la plus connue du modèle hypertextuel, le Web, a été créée au CERN par l'équipe de Tim Berners-Lee en 1989. Il s'agit d'une version "allégée" des visions initialement proposées pour l'hypertexte entre autres par T. Nelson et V. Bush :
Pas de gestion des droits d'auteur ;
Liens unidirectionnels se cassant lorsque la ressource disparaît ;
Pas d'aperçu des ressources liées ;
Pas de système d'annotation ni de gestion de versions.