Historique du Web et d'Internet
Dans sa conceptualisation, l'histoire de l'Internet et du Web remonte aux années 40 lorsque Vannevar Bush a rêvé d'un univers de documents interconnectés en réaction à l'explosion documentaire qu'il observait. Bien qu'il n'ait pas lui-même inventé le terme "hypertexte", c'est une des premières instances de ce concept. Dans sa concrétisation technique, c'est dans les années 60 que le premier nœud de ce qui deviendra Internet a été mis en place par l'équipe de Tim Berners Lee.

On remarque que l'écart entre les moments clés se raccourcit plus le temps avance. En fait, cette observation peut se faire plus globalement lorsque l'on observe l'adoption des technologies. Ceci est évident si on compare le temps pris pour atteindre 50 millions d'auditeurs pour certaines technologies marquantes dans notre histoire : la radio a pris 38 ans, la télévision 13 ans, Internet 4 ans, le iPod 3 ans, et Facebook 2 ans (source : Did you know 3.0? 2012, http://www.youtube.com/watch?v=YmwwrGV_aiE; il est à noter que d'autres sources donnent des chiffres un peu différents, par exemple https://twitter.com/Guglielminetti/status/919245063967911937, mais une tendance similaire est observable).
Si le rythme est essoufflant pour l'utilisateur et l'utilisatrice qui veut rester à jour, il l'est encore plus pour les organisations dont les activités sont étroitement liées avec ces environnements numériques. Cela leur demande d'être de plus en plus agiles dans leur intégration des technologies et de s'habituer aux changements perpétuels, ce qui n'est pas toujours facile d'un point de vue humain et organisationnel.
L'histoire d'Internet et du Web est jalonnée de moments clés qui seront décrits dans les sections qui suivent.
Internet
D'entrée de jeu, il est important de bien comprendre que les termes Internet et Web ne sont pas synonymes! On retrouve parfois une certaine confusion entre les deux termes. Plus précisément, on peut définir Internet ainsi :
A huge computer network available to everyone with a personal computer and a means to connect to it. It is the actual physical network made up of wires, cables, and satellites as opposed to the web, which is the multimedia interface to resources available on the Internet.
(Source : O'Leary et al.[1], 2019, p. 367)
Le Web est ainsi une des sphères d'Internet, Internet étant un réseau plus large regroupant différentes sphères (Web, courriel, FTP, etc.).
Internet est né d'une initiative militaire américaine. Le premier nœud du réseau ARPANET (Advanced Research Project Agency Network) à l'origine d'Internet a été mis en place en 1969. Avant l'apparition du Web, les échanges sur Internet étaient uniquement textuels. Leiner et al. (1997)[2] précisent qu'une des clés du développement rapide d'Internet est le fait que la documentation, et plus particulièrement les spécifications et les protocoles, était accessible gratuitement et librement.
Web
Comme précisé dans la section précédente, le Web est une interface graphique à des contenus sur Internet :
Prior to the introduction of the web in 1992, the Internet was all text. The web made it possible to provide a multimedia interface that includes graphics, animations, sound, and video.
(Source : O'Leary et al.[1], 2019, p. 377)
Au cœur du Web se retrouve l'idée des documents interconnectés proposés en 1945 par Vannevar Bush. Dans son texte "As We May Think",[3] il propose l'idée d'une machine, nommée MEMEX, pour résoudre les problèmes liés à l'explosion documentaire. Cette dernière serait en effet en mesure de ranger et rendre accessible tous les documents en permettant :
La visualisation des documents sur microfilm sur un écran, documents pouvant être complétés par des images;
La localisation des documents;
L'inclusion de pistes associatives entre les documents.
Le néologisme "hypertexte" a été proposé par le philosophe et sociologue américain Theodore Nelson en 1965. Il est à l'origine du projet Xanadu dont l'objectif était de regrouper tous les documents de l'humanité. Ce système, accessible à tous, permettrait l'ajout de documents et la définition de liens entre ces derniers. Au départ, il s'agissait uniquement d'une conceptualisation sans implémentation. Depuis, des démonstrations ont vu le jour après bien des années, dont OpenXanadu en 2014[4].
Le premier logiciel hypertexte grand public, créé par Bill Atkinson, est HyperCard (Apple) en 1987, logiciel dont le développement s'est terminé en 1998. Il permettait de présenter des contenus multimédias sur des fiches virtuelles cartonnées, cartes qui pouvaient être liées entre elles par des boutons. Pour les curieux et les curieuses (ou les nostalgiques!), Internet Archive a mis en ligne en 2017 pour fêter les 30 ans d'HyperCard une collection de projets HyperCard.
Finalement l'application la plus connue du modèle hypertextuel, le Web, a été créée au CERN par l'équipe de Tim Berners-Lee en 1989. Il s'agit d'une version "allégée" des visions initialement proposées pour l'hypertexte entre autres par T. Nelson et V. Bush :
Absence de gestion des droits d'auteur;
Liens unidirectionnels se cassant lorsque la ressource disparaît;
Absence d'aperçu des ressources liées;
Absence de système d'annotation et de gestion de versions.
Le Web est passé par différentes phases (Web 1.0, Web 2.0 et Web 3.0) qui seront décrites dans les sections subséquentes.
Web 1.0 : Les premières années "statiques" du Web
La "première version du Web", le Web 1.0 en quelque sorte que certains désignent comme un Web de documents, correspond à un Web où un petit nombre d'internautes étaient des créateurs ou créatrices de contenus, cette création demandant en effet des compétences informatiques plus avancées. La majorité des internautes était ainsi des observateurs ou des observatrices pouvant chercher parmi les informations existantes et les consulter. Maignien (2014) le compare à une bibliothèque distribuée sans murs :
Le modèle documentaire est alors clairement celui d'une bibliothèque distribuée, sans murs, autrement appelée bibliothèque virtuelle ou numérique, mais où l'information n'est pas classée de façon hiérarchisée, dans un arbre, mais distribuée en graphe (il existe autant de relations non hiérarchisées que de liaisons possibles entre les documents ou des parties de ces documents).
(Source : Maignien, 2014[5], p. 78)
Web 2.0 : Le Web participatif
La génération suivante, le Web 2.0, est un phénomène à la fois technologique et social, ce que fait bien ressortir cette définition :
Web doté d'outils et de contenus interactifs qui permettent aux internautes de participer à la création de contenus Web, de partager de l'information en ligne et de communiquer entre eux.
(Source : Grand dictionnaire terminologique, 2018, http://gdt.oqlf.gouv.qc.ca/ficheOqlf.aspx?Id_Fiche=26519897)
Les mots-clés ici sont "participer", "création de contenus" et "partager". Certains services et certaines technologies phares sont associés au Web 2.0.
Services/Technologies | Définition | Exemples |
|---|---|---|
Blogues | "Site Web ou section de site Web généralement tenus par une seule personne, consacrés à une chronique personnelle ou à une thématique particulière présentées sous forme de billets ou d'articles." (OQLF, 2018, http://gdt.oqlf.gouv.qc.ca/ficheOqlf.aspx?Id_Fiche=8370242) | |
Microblogues | "Blogue permettant de communiquer en temps réel au moyen de messages courts de 140 à 240 caractères, le plus souvent par l'intermédiaire d'une plateforme de microblogage, afin de partager de l'information avec une communauté d'internautes. " (OQLF, 2018, http://gdt.oqlf.gouv.qc.ca/ficheOqlf.aspx?Id_Fiche=26502311) | |
Wikis | "Site Web collaboratif où chaque internaute visiteur peut participer à la rédaction du contenu. " (OQLF, 2011, http://gdt.oqlf.gouv.qc.ca/ficheOqlf.aspx?Id_Fiche=8362053) | |
Réseaux sociaux | Environnements où l'utilisateur se définit un profil (personnel ou professionnel) et réseaute avec d'autres utilisateurs | Facebook (personnel) LinkedIn (professionnel) |
Plateformes de partage de ressources | Plateformes facilitant la composition de collections de ressources diverses et le partage de ces dernières | Flickr (photographies) YouTube (vidéos) Slideshare (présentations powerpoint) |
Fils de syndication | "Fil d'information consistant en un fichier XML, généré automatiquement, dont le contenu formaté, exploitable dynamiquement par d'autres sites Web, est récupérable par l'entremise d'un agrégateur qui permet de lire le nouveau contenu de ce fil répertorié, dès qu'il est disponible." (OQLF, 2006, http://gdt.oqlf.gouv.qc.ca/ficheOqlf.aspx?Id_Fiche=8869144) | Formats les plus connus : RSS et ATOM |
Folksonomies | "Système de classification collaborative et spontanée de contenus Internet, basé sur l'attribution de mots-clés librement choisis par des utilisateurs non spécialistes, qui favorise le partage de ressources et permet d'améliorer la recherche d'information." (OQLF, 2006, http://gdt.oqlf.gouv.qc.ca/ficheOqlf.aspx?Id_Fiche=8351986) | Se retrouvent par exemple sur les plateformes de partage de ressources pour décrire les ressources ou sur les blogues pour décrire les billets |
L'expression Web 2.0 a été utilisée pour la première fois en 2004 par l'équipe d'O'Reilly Media qui, reprenant la métaphore des numéros de version pour les logiciels, voulait indiquer une version améliorée du Web. Certains lui préfèrent maintenant l'expression Web social qui est en effet une de ses principales facettes. À ses débuts, certains voyaient le Web 2.0 comme un effet de mode et, à l'autre extrême, d'autres le percevaient comme un changement de paradigme. Les chiffres, qui croissent d'année en année, montrent sans l'ombre d'un doute qu'il ne s'agissait pas d'un effet de mode.
Type | Plateforme | Chiffres | Source |
|---|---|---|---|
Partage de ressources | Plus d'un milliard d'utilisateurs | https://www.statista.com/statistics/272014/global-social-networks-ranked-by-number-of-users/ (Janvier 2022) | |
YouTube | Plus de 2 milliards d'utilisateurs qui se connectent mensuellement Plus de 500 heures de contenu téléchargées par minute | https://www.youtube.com/intl/fr/about/press/ (2022-09-23) | |
Réseaux sociaux | Plus de 850 millions d'utilisateurs Plus de 200 pays et territoires | https://about.linkedin.com/fr-fr (2022-09-23) | |
Plus de 3 milliards d'utilisateurs Plus de 140 milliards de messages par jour | https://about.fb.com/company-info/ (2022-09-23) | ||
Rédaction collaborative | Wikipédia | 59 591 247 articles 2 456 889 articles en français 329 langues actives | https://meta.wikimedia.org/wiki/List_of_Wikipedias (2022-09-23) |
Micro-blogosphère | 436 millions d'utilisateurs | https://www.statista.com/statistics/272014/global-social-networks-ranked-by-number-of-users/ (Janvier 2022) |
Si on peut hésiter à parler d'une révolution, il s'agit très clairement d'une évolution tant des technologies que de leur utilisation. L'internaute qui le désire a maintenant à sa portée des technologies qui lui permettent de passer, s'il ou elle le désire, d'un rôle uniquement d'observation à un rôle de création, que ce soit dans ses activités personnelles ou professionnelles. Les internautes utilisent le Web 2.0 sur une base personnelle, mais aussi professionnelle, dans un cadre public ou privé, que ce soit pour informer et s'informer (à la « Web 1.0 »), mais aussi pour collaborer, réseauter ou échanger dans le cadre de leurs activités.
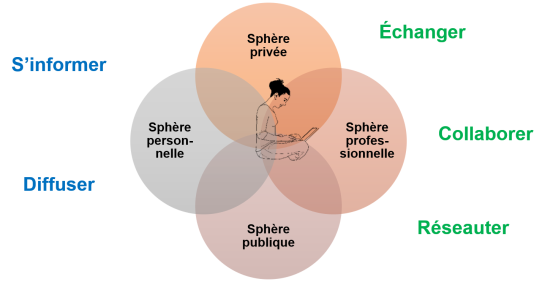
Dans l'univers du Web 2.0, on observe que les sphères publique et privée, personnelle et professionnelle deviennent perméables, leurs frontières étant plus floues. Par exemple, certains blogueurs mélangent parfois anecdotes personnelles et réflexions liées à leur travail sur leurs blogues. Le caractère privé de certaines formes d'expression, comme les journaux intimes, s'ouvre à la sphère publique, par exemple sur les blogues et les réseaux sociaux.
Adoption du Web 2.0 au Québec
L'utilisation faite des technologies du Web 2.0 est aussi tributaire du contexte des internautes. Une fracture numérique existe toujours pour certaines régions ou certains pays ayant un accès limité à ces plateformes pour des raisons économiques ou sociales. Au Québec, la population est globalement branchée et active sur les réseaux sociaux comme le montrent les résultats de l'enquête NETendances, anciennement menée par le Cefrio et plus récemment par l'Académie de la transformation numérique (ATN) :
Au quotidien en 2021, c'est 82 % des adultes québécois qui utilisent Internet plusieurs fois par jour et 8 % environ une fois par jour.
(ATN. 2021. NETendances 2021 : Portrait numérique des foyers québécois. Volume 12, no 4, p. 6. https://api.transformation-numerique.ulaval.ca/storage/584/netendances-2021-portrait-numerique-des-foyers-quebecois.pdf)
En 2021, 78 % des adultes québécois confirment utiliser un ou plusieurs réseaux sociaux comme Facebook, Twitter, YouTube, etc. Ce pourcentage d'utilisation est plus élevé chez les adultes âgés de 18 à 54 ans (90 %), les diplômés d'études collégiales (87 %) et universitaires (82 %) de même que les femmes (82 %). Quant aux non-utilisateurs des réseaux sociaux, ils représentent 14 % de l'ensemble des adultes québécois, et plus spécifiquement 19 % des hommes comparativement à seulement 9 % des femmes.
(ATN. 2021. NETendances 2021 : Actualités en ligne, réseaux sociaux et balados. Volume 12, no 8, p. 8. https://api.transformation-numerique.ulaval.ca/storage/644/netendances-2021-actualites-en-ligne-reseaux-sociaux-et-balados.pdf)
On retrouve plusieurs initiatives d'exploitation des plateformes 2.0 entre autres au sein des institutions culturelles québécoises.
Initiatives | But(s) |
|---|---|
Projets Wiki de BAnQ | « Ces projets visent à mettre en valeur les fonds et les collections de BAnQ, à rendre disponibles aux wikimédiens les ressources numérisées de l'institution et à contribuer à l'enrichissement des articles de Wikipédia (et ses projets frères) concernant le Québec, le Canada français et, plus largement, l'Amérique française. » |
Projets Wiki de la Cinémathèque québécoise https://fr.wikipedia.org/wiki/Wikipédia:Cinémathèque_québécoise | « La Cinémathèque québécoise s'investit dans la production et la diffusion de connaissances libres sur le cinéma québécois. Depuis septembre 2017, nous organisons notamment des activités citoyennes dans le but d'enrichir les projets Wikimédia dans ce domaine. » |
Café des savoirs libres | « Le Café des savoirs libres est un collectif montréalais de bibliothécaires, enseignants, chercheurs et autres passionné(e)s qui organise des rencontres de partage, des projets et des événements autour des savoirs libres et des communs numériques. » |
(Source d'inspiration : compte-rendu de la conférence-midi du 21 septembre 2017 sur la culture ouverte et le savoir libre par @bibliomancienne (Marie D. Martel) https://bibliomancienne.com/2017/09/22/culture-ouverte-et-savoir-libre-a-lebsi-sqil-copibecpasenmonnom/)
Web 3.0 : Le Web sémantique
Le World Wide Web Consortium (W3C)définit le Web sémantique ainsi :
The Semantic Web provides a common framework that allows data to be shared and reused across application, enterprise, and community boundaries. It is a collaborative effort led by W3C with participation from a large number of researchers and industrial partners.
L'idée centrale de ce qu'ils identifient comme un Web de données est celle d'un Web où les documents sont « enrichis » de manière à les rendre compréhensibles non seulement aux humains, mais aussi aux machines pour en faciliter la réutilisation. Cet enrichissement se fait à l'aide de métadonnées[7] permettant de décrire différents aspects des documents (par exemple, l'auteur, la date de création).
En fait, les folksonomies du Web 2.0 représentent une certaine couche « sémantique » ajoutée aux ressources et illustre le potentiel du « Web sémantique » en ce qu'elles permettent la création de nouvelles connaissances; « certaine » car c'est souvent une sémantique plus personnelle que collective qu'on y retrouve comme les étiquettes que l'on met à des photos sur Flickr par exemple. À un certain moment, parmi les étiquettes les plus populaires sur Flickr se retrouvait le mot "me" comme plusieurs utilisateurs l'employaient pour les photos où ils se retrouvaient!
Les applications composites – ou les mashups – que l'on retrouve sur le Web 2.0 démontrent l'intérêt du croisement de diverses données. Pensons par exemple à la possibilité d'explorer les photos déposées sur Flickr à l'aide d'une carte (https://www.flickr.com/map). La carte créée est le résultat du croisement des étiquettes géographiques apposées par les utilisateurs de Flickr à leurs photos avec une carte.
Cette idée d'ajouter aux documents du Web une couche sémantique pour en faciliter le partage et la réutilisation est attribuée à Tim Berners-Lee. Une des premières mentions de cette idée lui est attribuée lors de l'International World Wide Web Conference en 1994. Le Web sémantique est ainsi une extension du Web que l'on connaît par l'ajout de cette couche sémantique et le développement de technologies permettant de l'exploiter. Différents standards y sont rattachés que Bermès et coll.[8] (2013, p. 28) décrivent ainsi :
Ainsi, le Web sémantique a pour objet de fournir des standards qui vont rendre possible ce Web plus intelligent et plus efficace. Ces standards incluent le modèle RDF (*), des outils comme RDFS (*) (RDF Schema) et OWL (*) (Web Ontology Language) pour décrire la sémantique et la logique des données, et aussi des standards pour manipuler et traiter les données, comme SPARQL (*), le langage et protocole de requête de RDF.
Dans leur ouvrage, ces auteurs s'intéressent au Web sémantique en bibliothèque et espèrent réussir par cet ouvrage à "mobiliser vos [bibliothécaires] compétences d'analyse de l'information et de traitement des données pour vous [bibliothécaires] montrer comment elles peuvent être mises en valeur dans le nouvel environnement apporté par le Web sémantique." (Bermès et al., 2013, p. 13). Comme Da Sylva[9] le précise (2017, p. 28), Bermès et al. dans leur ouvrage reconnaissent le rôle des bibliothèques dans le Web sémantique, rôle en continuité avec leurs missions et leurs activités traditionnelles. Il importe ainsi comme professionnelles et professionnels de l'information d'en connaître les bases et tout particulièrement les types de données qu'on y retrouve, soit les données ouvertes liées décrites plus loin dans les notes de cours.
Exemple : Google Knowledge Graph
Un exemple du Web sémantique que l'on croise fréquemment dans nos recherches sur le Web est le Google Knowledge Graph. En effet, on voit apparaître lors de certaines recherches dans le moteur de recherche Google un encart à la droite de la liste des résultats retournés qui présente des informations souvent factuelles en lien avec la recherche. C'est le cas par exemple si vous faites une recherche sur une personnalité connue ou un pays. Cet encart est produit par la mise en relation de plusieurs jeux de données distincts en lien avec l'objet de votre recherche. C'est un exemple du potentiel du Web sémantique qui permet, par la couche sémantique ajoutée à certaines données, de générer de nouvelles données (les encarts de Google Knowledge Graph). Plus d'informations sur cette fonctionnalité sont disponibles sur le blogue de Google à l'URL https://googleblog.blogspot.com/2012/05/introducing-knowledge-graph-things-not.html.