Modèle relationnel
Le deuxième modèle que l'on retrouve souvent en contexte documentaire est celui des SGBD relationnels. Le mot "modèle" prend dans ce cas-ci tout son sens : avant d'être implémenté sur un ordinateur, son créateur, l'informaticien britannique Edga Frank "Ted" Codd, l'a défini mathématiquement formellement en 1970. Le premier produit basé sur ce modèle a vu le jour à la fin des années 70. De cette manière, il était possible d'éviter les problèmes rencontrés par certains modèles précédents, notamment le modèle réseau et le modèle hiérarchique, qui, n'ayant pas été formellement définis, mais plutôt directement implémentés, n'ont pas passé le test du temps et sont devenus obsolètes.
Il s'agit du modèle encore le plus utilisé actuellement. Beaucoup de systèmes intégrés de bibliothèques (SIGB) et autres applications documentaires sont construits sur des SGBD relationnels. Il est aussi très présent au niveau des systèmes d'information Web, quoiqu'il ne soit plus le seul! Ses limites pour les systèmes distribués à grande échelle sur le Web comme Twitter et Facebook ont conduit à l'apparition des familles de bases de données NoSQL (Not Only SQL) qui seront abordées rapidement un peu plus tard.
Remarque : Contexte des exemples
Afin d'illustrer nos propos, nous utiliserons la base de données fictive Dépenses Papeterie développée avec le SGBD relationnel Base de LibreOffice. Cette base de données, inspirée du TP Tableur, contient les informations sur les dépenses en papeterie de la firme ABC Courtage informationnel. On y retrouve de l'information sur les items achetés (champs ID_ITEM pour un numéro d'identification, ITEM pour le descriptif de l'item et COMMENTAIRE pour des commentaires sur les items), leur coût unitaire (champ COUT_UNITAIRE), le nombre d'items achetés (champ NBRE), la date d'achat (champ DATE), la ou les personnes ayant effectué l'achat (champ ID_RESPONSABLE pour un numéro d'identification, NOM pour le nom) et des commentaires sur l'achat (champ COMMENTAIRE).
Types de SGBD relationnels
On retrouve des SGBD relationnels de taille variable selon les contextes et les besoins auxquels ils répondent.
Petite pointure = SGBDR personnels | Grande pointure = SGBDR corporatifs |
|---|---|
|
|
On peut distinguer deux scénarios principaux d'implantation des SGBD relationnels :
Scénario 1 : Base de données relationnelle sur un ordinateur personnel
Un seul utilisateur à la fois
Par exemple Access (Microsoft Office), Base (LibreOffice), FileMaker Pro
Recherche d'information directement dans le SGBD via des assistants (recherche simple) ou SQL (recherche experte)
Entrée des données directement dans le SGBD (pour l'administrateur(trice) de données) ou via un ou des formulaires préparés dans le SGBD (pour les responsables de contenu)
Présentation des données à partir de rapports préparés dans le SGBD
Scénario 2 : Base de données relationnelle sur le Web
Architecture distribuée permettant de multiples utilisateurs et des systèmes d'exploitation variés (accès via un navigateur Web)
Par exemple, le SGBD MySQL sur un serveur Web
Recherche d'information directement dans le SGBD (pour l'administrateur(trice) de données) ou via des interfaces Web (pour le grand public)
Entrée des données directement dans le SGBD (pour l'administrateur(trice) de données) ou via un ou des formulaires HTML (pour les responsables de contenu)
Présentation des données à l'aide de pages Web dynamiques (par exemple en PHP ou en ASP)
Dans le cadre du TP Base de données, vous développerez une base de données de petite pointure selon le premier scénario. Bien que le scénario 2 soit de plus en plus présent, il implique des aspects de développement Web qui vont au-delà des attentes pour ce cours (il s'agit toutefois du scénario retenu pour le cours SCI6306!).
Structure de données du modèle relationnel
Les SGBD relationnels ressemblent aux SGBD textuels quant à l'unité de base utilisée pour structurer les données, soit la table de données. Deux différences importances existent cependant à ce niveau.
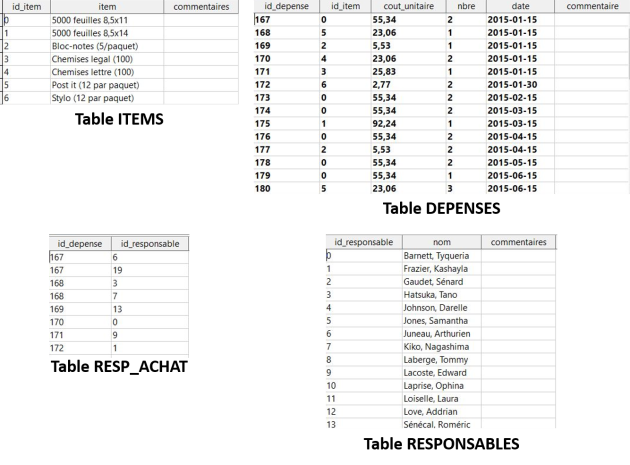
Premièrement, une base de données relationnelle peut comporter plus d'une table de données, les différentes tables étant reliées entre elles. Dans l'exemple utilisé, on retrouve quatre tables de données comme illustré ci-dessous, soit une table pour gérer la liste des items achetés (table ITEMS), une table pour gérer le détail des achats (table DEPENSES), une table pour gérer la liste des personnes responsables des achats (table RESPONSABLES) et une table pour faire le lien entre un achat et la ou les personnes qui en sont responsables (table RESP_ACHAT) :

Deuxièmement, une cellule dans une table de données ne peut comporter qu'une et une seule valeur :
On ne peut ainsi y retrouver d'occurrences multiples. C'est ce qui explique la table RESP_ACHAT qui permet d'associer plus d'un responsable à un achat. Remarquez dans cette table, pour la dépense #167, qu'on retrouve justement deux lignes, une ligne par responsable.
De plus, on ne peut y retrouver de cellule vide; pour un champ facultatif, l'absence de données est représentée par la valeur NULL. Les SGBD varient quant à l'affichage des valeurs nulles. Dans l'exemple ci-dessous, Base laisse tout simplement la cellule sans contenu. Dans MySQL, un autre SGBD relationnel, il indique explicitement NULL.
Ces deux différences font en sorte que leur modélisation se fait différemment, comme nous le verrons un peu plus tard.
Opérations possibles pour le modèle relationnel
La "sensibilité au texte" du modèle textuel ne se retrouve pas dans le modèle relationnel :
Les opérateurs de distance ne s'y retrouvent que sous certaines conditions et sont ainsi moins accessibles.
Les index ne sont pas nécessaires pour la recherche. La recherche peut en effet se faire tant à partir d'un index (recherche indexée) que sans index (recherche séquentielle).
On ne retrouve qu'un index mots, index que l'on ne peut consulter et sur lequel peu de contrôle est donné.
Par contre, le langage d'interrogation SQL (Structured Query Language) offre une multitude d'opérateurs que l'on ne retrouve pas dans le modèle textuel, comme, par exemple :
Des opérateurs mathématiques (addition, soustraction, etc.)
Des opérateurs statistiques (moyenne, médiate, etc.)
Des opérateurs pour traiter le texte (extraction de caractères, longueur d'une chaîne, transformation de la casse, etc.)
Le langage d'interrogation permet de représenter des besoins d'information très complexes grâce à ces opérateurs et aux différentes fonctions du langage SQL (fonctions d'agrégation, sous-requêtes, union de requêtes, etc.). Ce que l'on perd en recherche textuelle, on le gagne en richesse des opérateurs et des fonctions disponibles. L'exemple ci-dessous illustre la possibilité de regrouper les données par année et par item afin de calculer le nombre total d'items achetés, leur coût unitaire moyen ainsi que le coût total :

Modélisation d'une base de données relationnelle
La modélisation sémantique d'une base de données relationnelle permet d'ajouter à la compréhension d'une base de données et d'ainsi pouvoir répondre plus intelligemment aux interactions de l'utilisateur. Cette modélisation est utile au processus de conception systématique des bases de données. Elle se fait habituellement en dehors du SGBD.
L'objectif de cette modélisation est de représenter une certaine réalité selon le modèle relationnel pour pouvoir construire, par la suite, une base de données relationnelle. Du fait qu'une base de données relationnelle peut contenir plusieurs tables, la modélisation ne peut se contenter, comme pour le modèle textuel, de s'attarder uniquement aux champs à inclure dans la base de données. Il faut dans un premier temps conceptualiser la réalité à y représenter pour la découper en ses différentes composantes. Plusieurs approches peuvent être utilisées pour modéliser une BD, dont l'approche entités-relations (E-R) qui est une des plus connues et utilisées.
Cette approche est fondée sur le modèle E-R défini par Chen (1976) et raffiné par la suite. On y retrouve représentés plusieurs objets sémantiques :
Entités : objets que l'on peut et veut distinguer (par exemple, des dépenses, des items, etc.).
Relations : connexions entre des entités (par exemple, des achats qui relient des dépenses à des personnes responsables). Une relation possède une cardinalité qui représente la manière dont les enregistrements des deux entités connectées sont liés.
Attributs : propriétés décrivant une entité ou une relation (par exemple, le nom d'une personne responsable) que l'on veut documenter dans la BD.
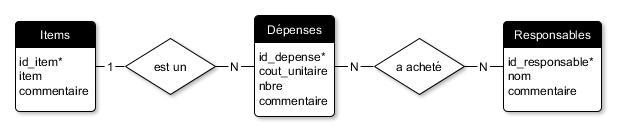
Un des résultats de la modélisation entités-relations est un diagramme Entités-Relations qui encapsule visuellement les différents objets sémantiques identifiés. Classiquement, les entités sont représentées par des rectangles, les relations par des losanges et les attributs par des ovales (les attributs, lorsqu'ils sont nombreux, peuvent aussi être représentés à même le rectangle de son entité).
Comme illustré ci-dessous, la modélisation du contexte de la base de données Dépenses Papeterie a permis de comprendre qu'on y retrouvait :
Trois entités : l'inventaire des types d'items de papeterie, les dépenses effectuées et la liste des personnes responsable des achats chez ABC Courtage informationnel
Deux relations :
Afin d'éviter de surcharger la base de données, seul le numéro des items (champ ID_ITEM) est conservé dans la table DÉPENSES. Pour connaître l'intitulé d'un item, la table DÉPENSES est liée à la table ITEMS. Une dépense n'est associée qu'à un seul item à la fois tandis qu'un des items de l'inventaire peut être associé à plusieurs dépenses. Il s'agit d'une relation de cardinalité 1-N.
Chaque dépense est associée potentiellement à une ou plusieurs personnes responsables des achats. La table DÉPENSES est ainsi liée à la table RESPONSABLES. La relation est de cardinalité N-N du fait qu'une dépense peut être associée à plus d'une personne et qu'une personne peut être associée à plus d'une dépense.
Plusieurs attributs : Pour chacune des entités, différentes caractéristiques sont enregistrées dans la base de données comme, par exemple, le coût unitaire pour une dépense ou le nom pour une personne responsable.
Une fois le diagramme Entités-Relations défini, l'étape suivante consiste à traduire cette conceptualisation en structure de tables et de champs et, tout comme pour les bases de données textuelles, à identifier les caractéristiques des champs nécessaires pour représenter le contexte désiré :
Nom du champ
Description du contenu du champ
Type de données (texte, nombre, date, ...)
Statut obligatoire ou facultatif
Index
Validation (par exemple, un masque pour la saisie pour respecter un format précis de date ou la saisie à partir d'une liste de mots prédéfinis)
Règles d'écriture s'il y a lieu
Exemples de contenu valide
Du fait de la relation entre les tables découlent deux éléments supplémentaires à définir :
Le ou les champs qui serviront de clé primaire[1] dans les tables. En effet, afin de pouvoir identifier de manière unique chacun des enregistrements dans une table, il faut qu'on y retrouve un champ (ou une combinaison de champs) dont les valeurs sont uniques. Par exemple, dans la base de données Dépenses Papeterie, les attributs indiqués dans le diagramme Entités-Relations par l'astérisque sont les champs de clés primaires. Chaque dépense possède son numéro unique (champ ID_DEPENSE), de même pour les items et les responsables.
Le ou les champs qui serviront de clé externe[2] dans les tables. Pour "faire le pont" entre deux tables liées, il faut avoir de part et d'autre un champ en commun qui, d'un côté sera la clé primaire et, de l'autre côté la clé externe. Si on reprend l'exemple des dépenses, pour pouvoir relier une dépense dans la table DEPENSES à la description complète de l'item dans la table ITEMS, on y ajoute le champ ID_ITEM comme clé externe pour pointer le champ ID_ITEM qui est la clé primaire de la table ITEMS.
Par exemple, à partir du diagramme Entités-Relations de la base de données Dépenses Papeterie, il est possible de déduire que la base de données possédera quatre tables, une pour chacune des entités (items, dépenses, responsables) et une pour le lien entre les dépenses et les responsables du fait de la cardinalité N-N. Il faudrait par la suite décrire chacune des tables pour préciser les caractéristiques des champs, la clé primaire, et, s'il y a lieu, la ou les clés externes. Par exemple, pour la table RESPONSABLES :
Champ | Type de données | Taille du champ (s'il y a lieu) | Statut |
|---|---|---|---|
id_responsable | numérique | 2 | Obligatoire |
nom | caractère | 100 | Obligatoire |
commentaire | caractère | 500 | Facultatif |
Clé primaire : id_responsable
Description du contenu des champs
id_responsable : identifiant numérique unique séquentiel attribué automatiquement par le système
nom : nom d'une personne responsable des achats sous la forme (Nom de famille, avec majuscule initiale) (virgule) (espace) (prénom au complet, si connu, initiale sinon, avec première lettre en majuscule) suivi, si nécessaire, de : (espace) (particule de nom de famille, telle qu'écrite dans le document) ou de : (espace) (initiale, en majuscule) (point)
commentaire : commentaire sur la personne responsable des achats (omettre la ponctuation finale)