Modèle textuel
Les premières utilisations des ordinateurs étaient pour des bases de données simples comme, par exemple, des données de recensement. Le premier modèle de données, dans ces contextes, a été le modèle de fichier plat. L'ajout de différentes caractéristiques et fonctionnalités spécifiquement pour les données textuelles l'a fait évolué dans certains cas vers un modèle textuel. Inmagic DB/TextWorks et CDS/ISIS sont deux exemples de bases de données basées sur le modèle textuel. Plusieurs bases de données commerciales accessibles en ligne sur des serveurs sont basées sur des SGBD textuels.
Remarque : Contexte des exemples
Afin d'illustrer nos propos, nous utiliserons la base de données fictive REPSCIE développée avec le SGBD textuel DB/TextWorks. Une version de démonstration de ce SGBD est disponible sur les postes des laboratoires de l'EBSI. La base de données RESPCIE est utilisée par le comité éditorial de la Revue prestigieuse des sciences de l'information essentielle pour effectuer le suivi des articles acceptés pour publication de la revue. On y retrouve de l'information sur les auteurs des articles (champs AU pour les noms et BIO pour une courte biographie), sur les réviseurs des articles (RE), sur les traducteurs des articles (champ TR) et sur les articles eux-mêmes (champs NO pour les identifier, TI pour le titre, RES pour un résumé, DAT pour la date de publication et DES pour des descripteurs).
Structure des données du modèle textuel
Dans le modèle textuel, la structuration des données se fait sur la base d'une seule table de données où chaque ligne représente un enregistrement (fiche) et chaque colonne, un champ. Un champ représente une caractéristique de l'enregistrement. Les enregistrements dans cette table ne sont pas reliés entre eux.
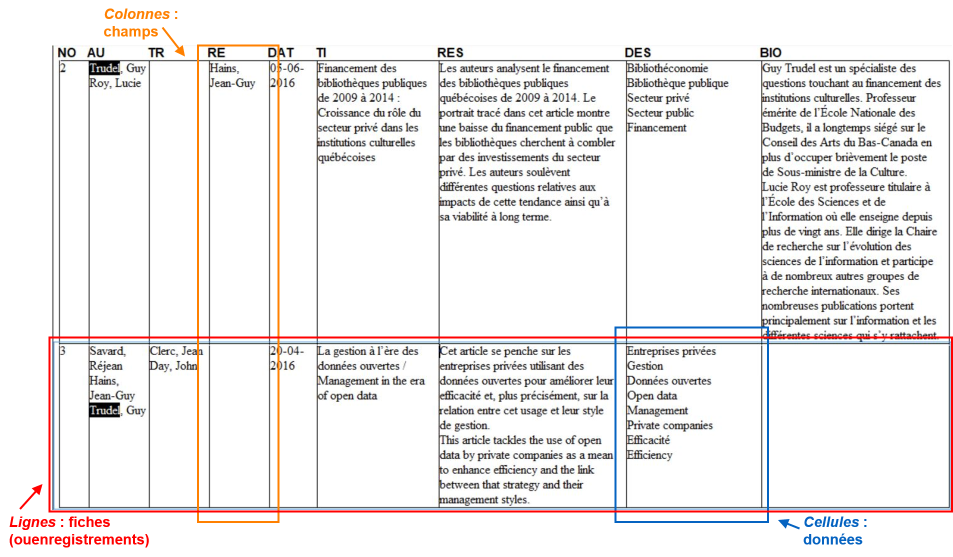
Au croisement d'un enregistrement et d'un champ se retrouve une cellule qui contient les données pour cet enregistrement et ce champ. Les données peuvent être de différents types : données textuelles, données numériques, dates par exemple.
On retrouve habituellement la possibilité dans ce modèle de données de retrouver plus d'une occurrence dans une cellule. Une occurrence est une valeur (entrée) distincte pour un champ et un enregistrement. Par exemple, pour la première fiche ci-dessus, on remarque qu'il y a deux entrées (deux occurrences) pour le champ AU comme cet article a deux auteurs : Trudel, Guy, Roy, Lucie. On parlera alors d'un champ à occurrences multiples.
Dans d'autres cas, un champ pourrait être défini à occurrence simple, c'est-à-dire qu'on ne pourra retrouver qu'une seule occurrence. C'est le cas pour le champ DAT comme un article est associé à une seule année de publication dans la base de données.
Finalement, on pourrait obliger la présence d'une occurrence ou plus pour des champs qui sont alors considérés obligatoires comme, par exemple, le champ AU comme il doit nécessairement y avoir au moins un(e) auteur(e). À l'opposé, on pourrait permettre l'absence d'occurrence pour un champ qui sera alors facultatif. C'est le cas du champ TR comme ce ne sont pas tous les articles qui nécessitent une traduction.
Opérations possibles pour le modèle textuel
Les bases de données du modèle textuel proposent des fonctionnalités bien adaptées aux données textuelles, c'est-à-dire des données composées surtout de phrases ou de mots.
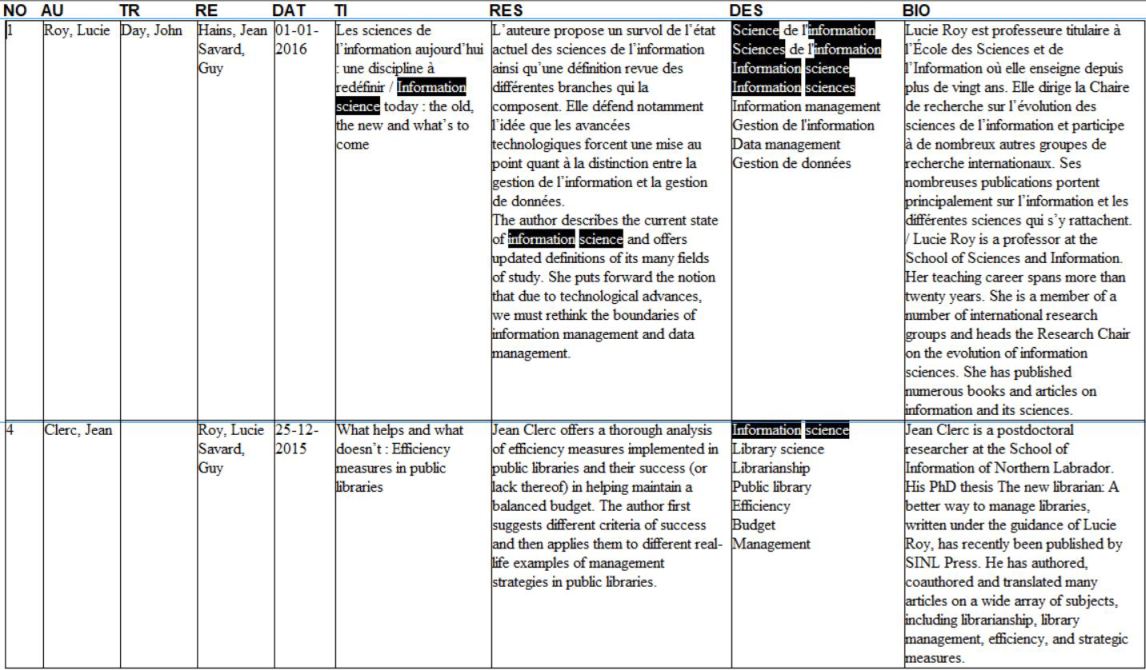
Premièrement, DB/TextWorks, en sus des opérateurs booléens (ET, OU, SAUF) pour la recherche, offre des opérateurs particulièrement pertinents à la recherche textuelle, soit des opérateurs de distance. Les opérateurs de distance permettent de chercher des mots à une certaine distance les uns des autres, dans l'ordre (par exemple "sciences" à quelques mots de "information" pour repérer "sciences de l'information" et "sciences de la communication et de l'information") ou dans le désordre (par exemple "sciences" à quelques mots de "information" pour retrouver tant "sciences de l'information" que "information science" comme illustré ci-dessous). Ils sont ainsi fort utiles pour préciser une requête de recherche.
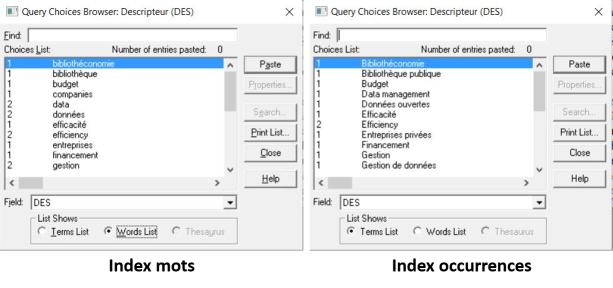
Deuxièmement, dans cet environnement, la recherche se fait nécessairement à partir des index construits sur la base des données présentes dans les champs. On parlera ainsi d'une recherche indexée. Un champ qui n'est pas indexé, dans ce SGBD, n'est pas cherchable. Cette base de données textuelle indexe les champs de deux manières décrites ci-dessous et illustrées par la suite :
Les données saisies dans un champ (par exemple, pour le champ DES, l'expression "Gestion de données") peuvent être découpées par mot dans un index mots (on retrouvera ainsi dans l'index mots une entrée pour "gestion" et une entrée pour "données").
Une entrée complète dans un champ (par exemple, "Gestion de données") peut se retrouver telle quelle dans un index occurrences sans être découpée.
Sans entrer dans les détails, l'existence de ces deux types d'index couplée au comportement des différents opérateurs de recherche permet des recherches textuelles plus précises.
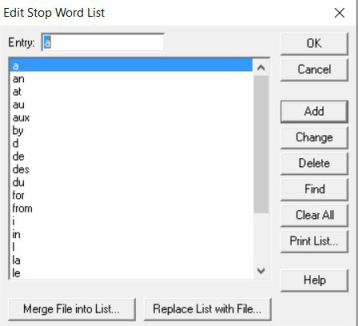
Finalement, on sent très bien la "sensibilité textuelle" dans ce SGBD du fait qu'il offre à ses utilisateurs, en sus des opérateurs de distance et des deux types d'index, une prise intéressante sur les index comme on peut, d'une part, les consulter comme illustré ci-dessus, mais aussi en contrôler le vocabulaire en rejetant les mots vides de sens :
Modélisation d'une base de données textuelle
La modélisation d'une base de données textuelle passera par les trois étapes habituelles d'une modélisation soit (1) sa conceptualisation, (2) sa représentation et (3) sa validation.
Conceptualisation
La conceptualisation d'une base de données textuelle consiste principalement à décider des champs qui permettront de bien représenter le contexte pour permettre les opérations désirées et à en définir les caractéristiques. Les champs dans une base de données représentent ainsi certaines caractéristiques sur lesquelles on désire conserver des informations. Dans l'exemple de la base de données REPSCIE, les concepteurs de la base de données ont eu à identifier, avec l'aide du comité éditorial de la revue, les caractéristiques qui leur seraient utiles pour gérer les articles acceptés pour publication. Ainsi, avant de développer une base de données dans un SGBD, il faut commencer par identifier les champs pertinents et leurs caractéristiques, notamment :
Nom du champ
Description du contenu du champ
Type de données (texte, nombre, date, ...)
Statut obligatoire ou facultatif
Type d'indexation (index mots et/ou index occurrences)
Occurrences simples ou multiples
Validation (par exemple, un masque pour la saisie pour respecter un format précis de date ou la saisie à partir d'une liste de mots prédéfinis)
Règles d'écriture s'il y a lieu
Exemples de contenu valide
Représentation
La représentation de cette conceptualisation (deuxième étape de la modélisation) se fera en consignant l'ensemble des champs et leurs caractéristiques dans le dictionnaire de données de la base de données. Ce dictionnaire servira à l'implantation, par la suite, de la base de données dans l'environnement retenu afin de définir la structure de données.
On y retrouverait, par exemple, les informations suivantes dans le dictionnaire de la base de données REPSCIE pour le champ AU :
Caractéristique | Valeur |
|---|---|
Nom du champ | AU |
Description du contenu | Liste des auteurs de l'article |
Type de données | Textuelle |
Statut | Obligatoire |
Type d'indexation | Index mots et Index occurrences |
Occurrences | Occurrences multiples |
Validation | Liste de validation des noms d'auteur |
Règles d'écriture s'il y a lieu | (Nom de famille, avec majuscule initiale) (virgule) (espace) (prénom au complet, si connu, initiale sinon, avec première lettre en majuscule) suivi, si nécessaire, de : (espace) (particule de nom de famille, telle qu'écrite dans le document) ou de : (espace) (initiale, en majuscule) (point) |
Exemples de contenu valide | Roy, Lucie Gardner, Richard K. Rochelière, Luc de la |
Validation
La validation consiste à s'assurer que le dictionnaire de données permet de bien représenter le contexte. Cela peut se faire entre autres par un retour auprès des personnes ayant émis le besoin d'une base de données pour qu'elles en vérifient l'exactitude.