SQL (niveau 2)
Regroupements (Clause GROUP BY)
La clause GROUP BY permet de faire des regroupements d'enregistrements par rapport à certains champs – regroupements qui permettent entre autres des opérations statistiques sur les éléments regroupés. Par exemple, dans INSCRIP, on pourrait vouloir regrouper ensemble tous les cours suivis par un étudiant ou une étudiante pour calculer le nombre de cours qu'il ou elle suit. On pourrait suivre une logique similaire pour compter le nombre de cours enseignés par les professeurs et professeures. Un autre exemple consisterait à regrouper ensemble toutes les notes des étudiants et étudiantes dans un cours pour calculer la moyenne du cours. Tous ces exemples exploitent la logique du regroupement.
La forme générique d'une requête comportant un regroupement est la suivante :
SELECT nom(s) de champs, valeurs calculées/fonctions d'agrégation
FROM nom(s) de tableWHERE condition(s)GROUP BY nom(s) de champsLogique du GROUP BY
Exemple : Calcul du nombre de cours suivis par les étudiant.e.s
Reprenons l'exemple du dénombrement des cours suivis par un.e étudiant.e. Le point de départ pour ce besoin est la table présentant toutes les inscriptions, soit le résultat de l'équijointure entre la table ETUD et la table SUIT obtenu par la requête SQL suivante :
SELECT *
FROM etud, suit
WHERE etud.no_etud=suit.no_etud ;
L'observation de la table de résultats ci-dessous nous permet de facilement compter "à l'oeil" le nombre de cours suivis par exemple par Claire Bretécher (3 cours). Ce que l'on veut est bien entendu non pas d'avoir à le calculer nous-mêmes manuellement, mais de le faire faire par une requête SQL. C'est ce que nous permet une clause GROUP BY.

On peut imaginer en quelque sorte que si on demande de regrouper la table résultant de l'équijointure sur la base du champ etud.no_etud (ce qui revient à ajouter à la requête la clause GROUP BY etud.no_etud), les valeurs des autres champs se regroupent dans une même cellule comme suit :
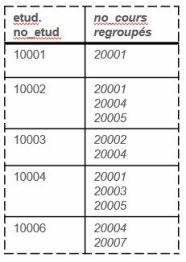
Il est alors possible d'appliquer différentes opérations - des fonctions d'agrégation par exemple - sur ces valeurs regroupées. On peut entre autres utiliser la fonction d'agrégation COUNT() qui permet de dénombrer les valeurs regroupées, ce qui est justement ce que l'on cherche! La requête SQL complète pour ce besoin serait ainsi :
SELECT etud.no_etud, nom, COUNT(no_cours) as 'Nbre cours'
FROM etud, suit
WHERE etud.no_etud=suit.no_etud
GROUP BY etud.no_etud;
Cette requête produira la table de résultats suivante :
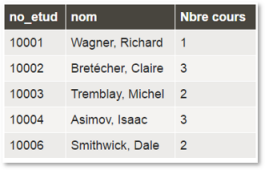
À noter : la fonction COUNT() a été appliquée au champ no_cours. Il faut faire bien attention au champ utilisé. Si vous utilisiez un champ qui est facultatif, les lignes où le champ est vide ne seraient pas comptées. On peut aussi demander de compter non pas un champ, mais la ligne au complet en utilisant l'astérisque ainsi : COUNT(*).
Exemple : Calcul de la moyenne globale obtenue par les étudiant.e.s pour la session
Prenons maintenant l'exemple du calcul de la moyenne obtenue par les étudiant.e.s pour la session. La table de résultats de base, avant le regroupement, peut s'obtenir simplement en exploitant la table SUIT (si on ne sent pas le besoin d'avoir les noms des étudiants et étudiantes) :
SELECT no_etud, note
FROM suitWHERE note_p;
Remarquez la présence de la condition WHERE note_p. Cette dernière permet de s'assurer de ne prendre en considération que les vraies notes et ainsi d'omettre le "zéro" par défaut pour les cours dont les notes n'ont pas encore été saisies. Une condition devant retourner VRAI ou FAUX, il suffit ici d'aller vérifier la valeur du champ note_p.
Comme on veut obtenir la moyenne par étudiant et étudiante, le regroupement se fera sur la base du champ no_etud en ajoutant à la requête SQL la clause GROUP BY no_etud. Les notes seraient ainsi mises ensemble pour chaque étudiant et étudiante :
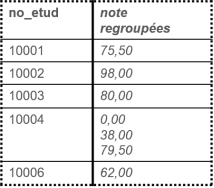
Maintenant que voilà les notes regroupées, il est possible d'y appliquer la fonction AVG() qui permet de calculer une moyenne (average). La requête SQL finale se lirait ainsi :
SELECT no_etud, AVG(note)
FROM suitWHERE note_pGROUP BY no_etud ;
La table de résultats retournée serait la suivante :
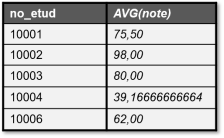
Syntaxe : Principales fonctions d'agrégation
SQL offre plusieurs fonctions d'agrégation, les principales étant les suivantes :
Fonction d'agrégation | Description |
|---|---|
COUNT(nom de champ) | Pour compter le nombre de valeurs d'un champ pour un regroupement d'enregistrements; |
MIN(nom de champ) | Pour identifier le minimum parmi les valeurs d'un champ pour un regroupement d'enregistrements |
MAX(nom de champ) | Pour identifier le maximum parmi les valeurs d'un champ pour un regroupement d'enregistrements |
SUM(nom de champ) | Pour obtenir la somme des valeurs d'un champ pour un regroupement d'enregistrements |
AVG(nom de champ) | Pour calculer la moyenne des valeurs d'un champ pour un regroupement d'enregistrements |
GROUP_CONCAT(nom de champ) | Pour concaténer dans une même valeur tous les éléments d'un groupe; il est possible de préciser un séparateur |
Une liste complète des fonctions d'agrégation peut être consultée à l'URL https://dev.mysql.com/doc/refman/8.0/en/aggregate-functions.html.
Exemple : Liste des cours, des étudiant.e.s inscrit.e.s, et du nombre d'étudiant.e.s inscrit.e.s, en ordre décroissant du nombre d'étudiant.e.s inscrit.e.s
Maintenant que la logique des regroupements a été présentée, nous ferons un dernier exemple impliquant son utilisation. Le besoin ici est pour obtenir, pour chacun.e des étudiant.e.s, la liste des cours qu'il ou elle suit ainsi que le nombre de cours suivis, le tout en ordre décroissant de nombre de cours suivis.
Décomposition du besoin :
Information affichée : Les champs pour décrire l'étudiant.e (no_etud et nom), les champs pour décrire les cours suivis (no_cours et titre), le nombre de cours suivis
Source de données : Table SUIT, table COURS, table ETUD
Jointures :
entre la table SUIT et la table COURS sur la base du champ NO_COURS
entre la table SUIT et la table ETUD sur la base du champ NO_ETUD
Conditions : aucune (uniquement les conditions de jointure décrites ci-dessus)
Regroupement : sur la base du numéro d'étudiant.e
Tri : en ordre décroissant du nombre de cours suivis
Requête SQL :
SELECT CONCAT(etud.no_etud, ' ', nom) as 'Étudiant.e', GROUP_CONCAT(CONCAT(cours.no_cours, ' ', titre) SEPARATOR '\n') AS 'Cours suivis', COUNT(cours.no_cours) AS 'Nombre de cours suivis'
FROM suit, cours, etud
WHERE cours.no_cours=suit.no_cours AND suit.no_etud=etud.no_etud
GROUP BY etud.no_etud
ORDER BY COUNT(cours.no_cours) DESC;
Cette requête donnera le résultat suivant :
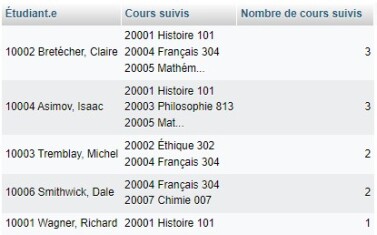
À noter :
La fonction CONCAT a été utilisée pour des questions de lisibilité afin de présenter dans une même colonne le numéro de l'étudiant.e et son nom (de même pour le numéro du cours et son titre).
La fonction GROUP_CONCAT a aussi été utilisée pour des questions de lisibilité comme elle permet de mettre ensemble les différentes valeurs regroupées dans une même cellule. Un retour de ligne, représenté dans phpMyAdmin par
\n, sépare les différentes valeurs sur des lignes distinctes. Si vous testez cette requête dans KeSQiL fait?, vous remarquerez qu'il ne comprend pas cette chaîne comme un retour de ligne et l'affiche à l'écran. Cela vient du fait que l'affichage est géré en HTML. Pour représenter le retour de ligne, il faudrait plutôt utiliser la balise<br/>!Des alias ont été utilisés pour s'assurer d'avoir des entêtes de colonne compréhensibles.
Le tri se fait sur la fonction d'agrégation et non à partir de son alias.
Union de requête (fonction UNION)
Il est possible d'unir les résultats de plusieurs requêtes en utilisant la fonction UNION. La seule exigence est que chacune des requêtes que l'on veut ainsi unir doit avoir le même nombre de colonnes dans sa table de résultats (peu importe la nature des données dans ces colonnes).
Exemple : Liste des cours avec des inscriptions ou ayant un.e professeur.e attitré.e
Pour certains besoins, on entrevoit parfois comment le faire en deux temps. Le besoin ici est d'avoir dans une même liste les cours avec des inscriptions ainsi que les cours ayant un.e professeur.e associé.e. Dans cet exemple, on sait par exemple comment identifier les cours avec des inscriptions :
SELECT DISTINCT cours.no_cours, titre
FROM cours, suit
WHERE cours.no_cours=suit.no_cours
ORDER BY cours.no_cours;
Cette requête permet d'obtenir la table de résultats suivante :
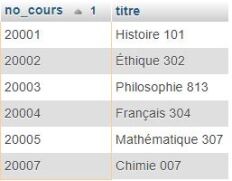
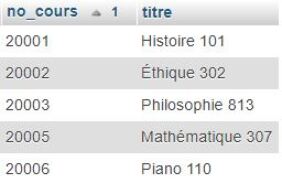
On sait aussi comment trouver les cours ayant un.e professeur.e associé.e :
SELECT no_cours, titre
FROM coursWHERE no_prof is not NULL
ORDER BY no_cours;
Cette requête donne la table de résultats suivante :
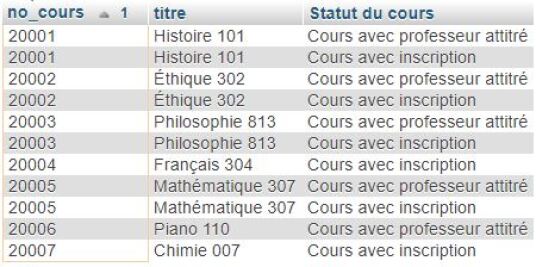
Ne reste ainsi qu'à les unir! Chacune des requêtes est mise entre parenthèses en ajoutant le mot-clé UNION entre les deux. De plus, comme on veut globalement trier les résultats, la clause ORDER BY sera sortie des requêtes. Finalement, une troisième colonne sera ajoutée à chacune des requêtes afin d'indiquer la nature des enregistrements sinon, une fois les deux tables de résultats mises ensemble, il sera difficile de savoir quels cours correspondent à des cours avec des étudiant.e.s inscrit.e.s et lesquels ont des professeur.e.s assigné.e.s. Un dernier petit détail : le prédicat DISTINCT dans la première requête peut être enlevé; il devient en effet inutile comme une requête UNION le fait automatiquement. La requête SQL obtenue est la suivante :
(SELECT cours.no_cours, titre, 'Cours avec inscription' AS 'Statut du cours'
FROM cours, suit
WHERE cours.no_cours=suit.no_cours)
UNION(SELECT no_cours, titre, 'Cours avec professeur attitré'
FROM coursWHERE no_prof is not NULL)
ORDER BY no_cours;
La table de résultats suivante sera retournée :
Exemple : Cours ayant des informations manquantes (local non assigné, professeur non associé, titre non défini)
Nous aborderons un dernier exemple où l'union peut être bien pratique. Le besoin ici est d'afficher la liste des cours pour lesquels certaines informations sont manquantes (soit le local, soit le professeur, soit le titre). Comme on sait bien comment aller chercher chacun des morceaux individuellement, la logique d'une union s'applique ici très bien.
Décomposition du besoin :
Information affichée : Les champs pour identifier le cours (no_cours et titre), le type d'information qui manque
Source de données :
Première requête : table COURS
Deuxième requête : table COURS
Troisième requête : table COURS
Jointure : aucune
Conditions :
Première requête : le local doit être manquant (valeur NULL)
Deuxième requête : le numéro du professeur ou de la professeure doit être manquant (valeur NULL)
Troisième requête : le titre du cours doit être manquant (valeur NULL)
Regroupement : aucun
Tri : en ordre décroissant du numéro de cours
Autre : utilisation de UNION entre les trois requêtes
Requête SQL :
(SELECT cours.no_cours, cours.titre, 'Local' AS 'Information manquante' FROM cours WHERE cours.local is NULL)
UNION(SELECT cours.no_cours, cours.titre, 'Professeur' FROM cours WHERE cours.no_prof is NULL)
UNION(SELECT cours.no_cours, cours.titre, 'Titre' FROM cours WHERE cours.titre is NULL)
ORDER BY no_cours;
Cette requête donnera comme résultat la table suivante :

Copies multiples d'une table
Et si l'on veut trouver les étudiant.e.s qui suivent à la fois deux cours en particulier (par exemple. '20001' et '20003')? On voudrait bien pouvoir faire une intersection au lieu d'une union, mais « INTERSECT » n'existe pas... Ajouter dans la clause WHERE une condition du type « suit.no_cours= '20001' AND suit.no_cours='20003' » ne fonctionnera pas non plus comme chaque ligne de la table COURS correspond à une seule inscription. Un.e étudiant.e suivant ces deux cours aura ainsi deux lignes pour ces deux cours; et les conditions dans une requête sont appliquées sur une seule ligne à la fois.
Ce que l'on voudrait, c'est avoir sur une même ligne dans la table servant de source de données pour une requête SQL pour un.e étudiant.e, deux des cours qu'il ou elle suit pour pouvoir faire une condition du type « suit1.no_cours='20001' AND suit2.no_cours='20003' »...
Comment faire? Utiliser deux copies de la table SUIT!
Une pour vérifier l'inscription au cours 20001
L'autre pour vérifier l'inscription au cours 20003
Il faut donc commencer par construire la requête qui nous permettra d'obtenir cette table. On y retrouvera deux versions de la table SUIT, l'une nommée SUIT1 et l'autre SUIT2 ainsi qu'une version de la table ETUD. Nous travaillons avec une seule version de la table ETUD comme on souhaite obtenir, pour une même personne, deux de ses cours. Il faut bien entendu "attacher" la table ETUD à ces deux tables SUIT sur la base du champ NO_ETUD :
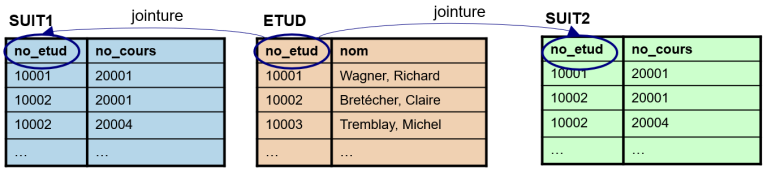
La requête SQL pour obtenir ce résultat est la suivante :
SELECT suit1.no_cours as "premier cours suivi", etud.no_etud, etud.nom, suit2.no_cours as "deuxième cours suivi"
FROM etud, suit AS suit1, suit AS suit2
WHERE etud.no_etud=suit1.no_etud
AND etud.no_etud=suit2.no_etud;
Les deux versions de la table SUIT sont nommées à l'aide d'alias dans la clause FROM. On obtiendrait ainsi la table de tous les couples de cours suivis par les étudiant.e.s :
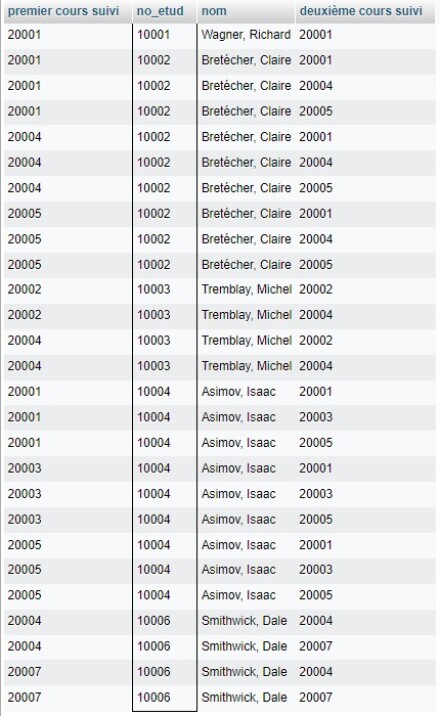
Ainsi, si on veut identifier les étudiant.e.s qui suivent les cours 20001 et 20004, il ne reste qu'à ajouter les conditions nécessaires à la requête :
SELECT suit1.no_cours as "premier cours suivi", etud.no_etud, etud.nom, suit2.no_cours as "deuxième cours suivi"
FROM etud, suit AS suit1, suit AS suit2
WHERE etud.no_etud=suit1.no_etud
AND etud.no_etud=suit2.no_etud
AND suit1.no_cours=20001
AND suit2.no_cours=20004;
Une seule ligne serait alors retournée, comme une seule étudiante suit en même temps ces deux cour :

Quelques fonctions/opérations utiles
Fonction/opération | Description |
|---|---|
Troncature (%) |
|
Masque (_) |
|
Concaténation (CONCAT) |
|
BETWEEN ... AND ... |
|
IF(condition, valeur si vraie, valeur si faux) |
|
IFNULL(champ/expression, valeur à afficher si NULL) |
|
IN |
|