<histoire>⤶
¤¤Très¤¤¤courte¤¤¤anecdote.⤶
</histoire>
Rendu typique en navigateur : 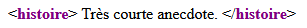
Copyright © 2005-2023 Yves MARCOUX; dernière modification de cette page : 2023-01-08.
INU3011 Documents structurés – Premier Tour d’horizon de XML
Index de ce texte — Index général du Tour d’horizon — Accueil du Tour d’horizon
Yves MARCOUX - EBSI - Université de Montréal
XML signifie Extensible Markup Language. XML 1.0 est le format normalisé de documents structurés le plus utilisé au monde. Il est l’objet de la recommandation REC-xml-20081126 du World Wide Web Consortium (W3C).
Comme il a déjà été mentionné dans Comment lire ce Tour d’horizon ?, tout document (ou fichier) XML est aussi un fichier texte. Ce qui distingue les documents XML des autres fichiers texte, c’est que leur contenu est conforme à un ensemble de règles syntaxiques précises, que l’on appelle le bien-formé XML, ou simplement le bien-formé (en anglais, well-formedness). Le contenu d’un fichier texte étant une suite de caractères, cela revient à dire que les caractères dans un document XML doivent se succéder selon des règles bien précises.
Un fichier texte qui respecte les règles du bien-formé est dit bien formé (sans trait d’union) et est appelé document ou fichier XML. Un fichier texte qui ne respecte pas le bien-formé est dit mal formé.
Un document XML est donc – par définition – bien formé. On précise parfois quand même « document XML bien formé », lorsqu’on veut insister sur le respect du bien-formé, souvent par opposition à un autre document qui, lui, serait mal formé.
L’expression « document XML mal formé », quant à elle, est un oxymore, puisqu’un document XML est par définition bien formé. On l’utilise quand même souvent, lorsqu’on veut justement attirer l’attention sur l’erreur ou les erreurs de bien-formé qui affligent le document. Pour être rigoureux, il faudrait dire document ou d’un fichier texte mal formé, et non « document XML mal formé », mais l’abus de langage est bien compris et accepté.
Essentiellement, les deux premiers textes du Tour d’horizon (celui-ci et Les entités en XML) présentent les règles du bien-formé et les constructions syntaxiques en fonction desquelles elles sont définies. Une construction syntaxique est simplement une suite de caractères consécutifs qui respecte une certaine forme et est considérée comme un tout dans la vérification des règles du bien-formé. Quelques-unes des constructions syntaxiques en XML sont les noms XML, les noms d’élément, les éléments et les balises; il y en a plusieurs autres. Certaines portent plusieurs noms (habituellement pour des raisons historiques); ainsi, un nom d’élément peut aussi s’appeler type d’élément et identificateur générique.
Nous appliquons les qualificatifs de « bien formé » et « mal formé » non seulement aux documents complets, mais aussi aux différentes constructions syntaxiques dont la forme correcte est définie par les règles du bien-formé. Nous dirons par exemple un nom XML bien ou mal formé, une balise bien ou mal formée, un élément bien ou mal formé, etc.
Toutes les règles du bien-formé ne sont pas incluses dans ce premier tour d’horizon, mais les plus importantes y sont. Une liste des omissions (délibérées) est donnée en annexe.
Parce que tout document XML est aussi un fichier texte, on dit que XML est un format basé sur le format texte. Beaucoup d’autres formats sont dans la même situation : RTF (Rich Text Format), TeX, HTML, pour n’en nommer que quelques-uns. Pour cette même raison, les documents XML peuvent tous être ouverts avec n’importe quelle application capable de traiter des fichiers texte, notamment le Bloc-notes, Notepad++ et TextEdit.
Un format de documents numériques comporte toujours deux niveaux de règles : le niveau syntaxique, constitué de règles sur le contenu des fichiers, et le niveau sémantique, constitué de règles d’interprétation du contenu des documents.
Dans le cas de XML, le niveau syntaxique est constitué des règles du bien-formé. Quant au niveau sémantique, il est très rudimentaire. La seule règle d’interprétation prévue dans la spécification XML (le texte qui définit XML comme format) est de considérer un document comme une structure hiérarchique d’information textuelle. Nous verrons sous peu comment certaines applications – en particulier les navigateurs Web – réalisent cette interprétation de base.
De la même façon que XML est basé sur le format texte, de nombreux formats sont basés sur XML, en ce sens que les documents conformes sont d’abord et avant tout des documents XML bien formés, mais respectent en plus des règles syntaxiques additionnelles propres au format. Au niveau sémantique, ces formats peuvent avoir des règles d’interprétation aussi complexes et sophistiquées que l’on peut imaginer. Par exemple, le domaine d’interprétation du format MEI, de la Music Encoding Initiative, est celui de la musique écrite.
Quand un format de documents A est basé sur un autre format B, on dit que A est une restriction ou spécialisation de B. Dans le cas de formats basés sur XML (c’est-à-dire quand B = XML), on peut aussi dire que A est un vocabulaire XML, un “tagset” ou un dialecte XML. À titre d’exemple, un des vocabulaires XML les plus connus est le XHTML, un format de pages Web. Un autre exemple est Scalable Vector Graphics (SVG), un format d’images vectorielles.
XML est un format normalisé développé par le W3C, ou World Wide Web Consortium, une communauté internationale se donnant pour mission le développement de normes pour le Web.
L’extension de noms de fichiers habituelle pour les fichiers XML est (vous l’aurez
deviné) .xml. Certains formats basés sur XML préconisent cependant
l’utilisation d’une extension différente, même si les documents sont des documents
XML à part entière. Ainsi, par exemple, les documents XHTML sont habituellement
nommés avec l’extension .xhtml et les documents SVG avec
.svg.
Tous les documents XML peuvent être ouverts avec n’importe quelle application capable de traiter les fichiers texte. Certaines applications plus spécialisées sont capables d’interpréter les documents XML, au moins pour en donner une représentation visuelle hiérarchique (ce qui correspond, rappelons-nous, à la sémantique rudimentaire prévue dans la spécification XML). Les navigateurs Web, notamment, sont dans cette catégorie.
Dans la plupart des systèmes d’exploitation courants, l’application par défaut
associée à l’extension .xml est un navigateur Web. Dans Windows 11, il
s’agit du navigateur Edge. Il est possible de modifier cette application par défaut.
Pour les fins du cours, si vous avez la possibilité de définir le navigateur Firefox
comme application par défaut associée à l’extension .xml, vous êtes
invitée à le faire. Sur les postes des laboratoires de l’EBSI, il est possible que
cette association soit déjà établie.
Rappel : Vous voudrez peut-être revoir les conventions de présentation des exemples et les modes de lecture du Tour d’horizon.
Voici un premier exemple de document XML :
<histoire>⤶
¤¤Très¤¤¤courte¤¤¤anecdote.⤶
</histoire>Rendu typique en navigateur :
Si vous regardez bien la façon dont le document est présenté par le navigateur, vous constaterez que ce dernier ne reproduit pas simplement le contenu du document XML caractère par caractère. En effet, comme nous venons de dire, le navigateur interprète le contenu du document XML et nous montre le résultat de cette interprétation :
Voici un exemple un peu moins minimaliste :
<liste>Voici deux items:<item>1</item><item>2</item></liste>Rendu typique en navigateur :
Cet exemple illustre encore mieux combien le navigateur « joue » librement avec les sauts de ligne et l’indentation. L’interprétation du navigateur porterait à penser que le contenu du document est quelque chose comme :
<liste>⤶
¤¤Voici deux items:⤶
¤¤<item>1</item>⤶
¤¤<item>2</item>⤶
</liste>
Pourtant, la source du document tient bel et bien sur une seule ligne.
Cette liberté que prend le navigateur avec les sauts de ligne et les indentations peut sembler excessive, mais elle vise uniquement à rendre plus facilement perceptible par l’œil humain la fameuse « structure hiérarchique » du document, qui est la sémantique intrinsèque à XML et sur laquelle nous reviendrons plus loin.
Cet exemple est aussi l’occasion de mentionner un autre aspect de l’interprétation
que font les navigateurs Web des documents XML. Notez le caractère "-" qui se trouve
au tout début du rendu du document. Ce caractère est en fait une puce cliquable qui
permet de « plier » une section du document. Une fois la section pliée, la puce se
modifie en un "+" ( ), que l’on
peut cliquer pour ramener la section à son état déplié. Essayez-le maintenant !
), que l’on
peut cliquer pour ramener la section à son état déplié. Essayez-le maintenant !
La consultation en navigateur Web d’un document XML peut donc être une interaction dynamique et non un simple affichage statique.
Les navigateurs Chrome et Edge – sur un ordinateur et non un dispositif mobile – utilisent ▸ et ▾ comme puces cliquables au lieu des "+" et "-" de Firefox, mais le comportement est le même.
Par défaut, c’est le rendu interprété d’un document XML qui est affiché par le navigateur, mais on peut toujours faire afficher le texte « brut » (non interprété) du document en faisant « afficher le code source de la page », exactement comme pour une page HTML (Clic-droit dans la fenêtre d’affichage puis choisir l’item approprié dans le menu contextuel). L’affichage du code source respecte la disposition du texte dans le fichier (les espaces et sauts de ligne), mais applique la même coloration syntaxique que dans le rendu interprété. Voici l’affichage du code source obtenu dans Firefox avec l’exemple précédent :
L’interprétation d’un document XML comme structure hiérarchique est certes intéressante, mais elle est loin d’être emballante. Si tout ce qu’on fait avec des documents XML est de les ouvrir en navigateur Web pour en voir la structure hiérarchique, il est difficile d’imaginer que XML est une des façons les plus utiles et versatiles de représenter l’information.
Malheureusement, dans le déroulement du cours, ce n’est pas avant plusieurs semaines que nous commencerons à faire autre chose avec les documents XML que d’en admirer la structure hiérarchique en navigateur Web… Pour vous donner un avant-goût de ce que nous ferons plus tard, voici un exemple de ce qu’un navigateur Web peut faire avec un document XML si on le lie à une feuille de style.
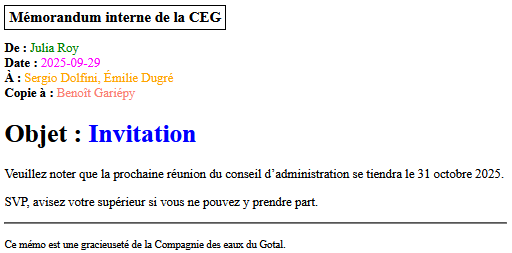
Le document suivant est lié à une feuille de style (sautons pour le moment les détails de comment on effectue un tel lien). Quand vous cliquerez sur le lien qui y mène, le rendu obtenu sera cette fois-ci très différent du XML brut. Essayez-le (puisque le document est stylé, vous pouvez le faire même sur une tablette ou un téléphone) !
<?xml-stylesheet type="text/xsl" href="memo.xsl" ?> <mémo-CEG> <date>2025-09-29</date> <auteur>Julia Roy</auteur> <destinataires> <nom>Sergio Dolfini</nom> <nom>Émilie Dugré</nom> </destinataires> <objet>Invitation</objet> <cc> <nom>Benoît Gariépy</nom> </cc> <corps> <par>Veuillez noter que la prochaine réunion du conseil d’administration se tiendra le 31 octobre 2025.</par> <par>SVP, avisez votre supérieur si vous ne pouvez y prendre part.</par> </corps> </mémo-CEG>Lien vers cet exemple (faites afficher la source pour vérifier qu’il s’agit bien de l’exemple ci-dessus !).
Rendu typique en navigateur :
Évidement, cette présentation est plutôt loufoque par son utilisation des couleurs, mais espérons qu’elle vous convaincra qu’il est au moins possible de présenter les documents XML d’une façon digeste pour l’humain. Notons en particulier que le stylage permet de modifier l’ordre de présentation des informations, par exemple la date et le nom de l’auteur sont intervertis dans le document stylé par rapport au document XML. Même chose pour l’objet du mémo et la liste de récipiendaires d’une copie conforme (cc).
Il est important de noter que l’interprétation d’un document XML n’est possible
que parce que son contenu est bien formé. En effet, si on présente à un
navigateur un fichier portant l’extension .xml, mais qui n’est pas bien
formé, le navigateur sera incapable de compléter l’interprétation et nous donnera
plutôt un message d’erreur, comme le montre le prochain exemple.
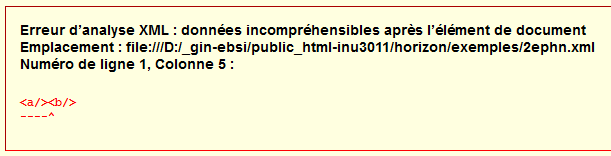
Même si nous n’avons encore rien dit des règles du bien-formé, vous ne serez probablement pas surpris d’apprendre que le document texte suivant n’est pas un document XML bien formé :
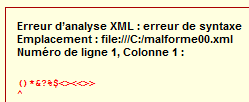
()*&?%$<><<>>Rendu typique en navigateur :
Le navigateur n’arrive pas à interpréter le document comme un document XML, puisque son contenu ne respecte pas le bien-formé.
Note : Difficulté possible à voir les messages d’erreur
Si vous n’obtenez pas directement de message d’erreur avec l’exemple précédent ou tout autre document XML mal formé, cela peut être dû à une particularité de votre navigateur Web :
À l’occasion, avec Firefox, il faut rafraîchir l’affichage pour voir le message d’erreur dans la fenêtre de navigation. Il faut cliquer dans la barre d’adresse puis appuyer sur Entrée (Ctrl+F5 ne suffit pas). Cela semble être un bogue intermittent dans certaines versions du navigateur.
Une autre façon de voir les messages d’erreur avec Firefox est d’ouvrir la console : Maj+Ctrl+K.
Si vous utilisez un de ces navigateurs, c’est une chose à garder en tête pendant la lecture du Tour d’horizon et lorsque vous créerez vos propres documents XML.
Si vous avez appliqué la lecture active au dernier exemple ci-dessus, autrement dit si vous l’avez ouvert dans oXygen, vous avez constaté qu’oXygen réagit lui aussi (comme les navigateurs Web) au fait que le document est mal formé. En effet, quelques secondes après l’ouverture du document, vous avez dû voir apparaître juste sous la fenêtre d’édition le message suivant :
Du contenu n'est pas autorisé dans le prologue.
Même si oXygen peut, à certains égards, sembler se comporter comme un simple éditeur de texte, il possède en fait de nombreuses fonctions spécifiques au XML. L’une d’elles est la constante vérification du bien-formé. Quelques secondes après chaque modification au document (ce délai est paramétrable), oXygen vérifie le document dans son entier pour voir si toutes les règles du bien-formé sont respectées. Si le document est mal formé, un message d’erreur est affiché. C’est un peu comme la vérification orthographique dans un logiciel de traitement de texte, mais appliquée aux règles syntaxiques de XML.
Indépendamment de cette vérification automatique, on peut aussi demander explicitement la vérification du bien-formé en faisant Document → Valider → Vérification du bien-formé, ou avec le raccourci-clavier Ctrl+Maj+W (le « w » s’expliquant par le nom anglais du bien-formé : well-formedness).
En contexte d’apprentissage, la possibilité de modifier à volonté un document et de voir en direct l’effet de nos modifications sur le bien-formé du document est une aide précieuse. C’est exactement ce que permet la lecture active préconisée pour le Tour d’horizon.
Le message d’erreur obtenu dans oXygen avec notre exemple mal formé nous fournit une excellente transition vers la prochaine section, dans laquelle nous aborderons concrètement le bien-formé, puisqu’il parle de « prologue ».
Entrons maintenant de pied ferme dans les règles du bien-formé.
Un document XML bien formé peut toujours être découpé de façon unique en trois sections contiguës (c’est-à-dire se suivant collées l’une à l’autre), dans cet ordre :
Chacune de ces sections est constituée d’une suite de caractères consécutifs, c’est-à-dire qui se suivent l’un après l’autre dans le fichier. Si une section est vide, elle est simplement constituée d’aucun (ou zéro) caractère. Par exemple, si le prologue est vide, le premier caractère que l’on rencontre dans le document est le premier caractère de l’élément-document. À moins d’avis contraire, nous ne considérons que les cas où le prologue et l’épilogue sont vides; le document XML se résume alors à un élément-document.
L’élément-document est la partie principale et essentielle du document, celle qui contient toute l’information véhiculée par le document. Quand le prologue et l’épilogue sont vides, elle constitue l’intégralité du document. Même quand le prologue et/ou l’épilogue ne sont pas vides, la section élément-document est typiquement beaucoup plus longue que les deux autres, étant porteuse de tout le contenu informationnel du document.
Nous verrons sous peu comment un élément-document doit être constitué, mais nous
pouvons déjà dire qu’un élément-document est un cas particulier d’un
élément XML, et que tous les éléments XML, sans
exception, commencent par le caractère "<" et se
terminent par le caractère ">". Ainsi donc, quand le prologue et
l’épilogue d’un document sont vides, le premier caractère du document est forcément
un "<" et le dernier un ">". (Notons qu’il peut y avoir
d’autres "<" et ">" ailleurs dans le document.)
Comme la plupart des exemples vus jusqu’ici, le document suivant a un prologue et
un épilogue vides, et ne consiste donc qu’en un élément-document. Tel qu’attendu,
les premier et dernier caractères du document sont bel et bien "<"
et ">" :
<saga>Très longue histoire.</saga>Rendu typique en navigateur :
Nous verrons ci-dessous que le prologue et l’épilogue peuvent en fait contenir des caractères blancs, des commentaires et certaines autres choses.
Donc, si vous avez déjà vu les mots « balise » et « élément » utilisés comme synonymes, retenez qu’ici :
balise ≠ élément
La structuration de l’information dans un document XML se fait par l’insertion de
balises (en anglais tag) à différents
endroits dans le document. Une balise est une courte chaîne de caractères
consécutifs. Comme les éléments, toutes les balises sans exception
commencent par le caractère "<" et se terminent par le caractère
">". En fait, si les éléments commencent et se terminent toujours par
"<" et ">", c’est simplement qu’ils commencent et se
terminent obligatoirement par une balise.
On distingue trois sortes de balises :
<" est suivi immédiatement d’un nom XML
(essentiellement, une suite de lettres et/ou de chiffres commençant par une lettre
– détails ci-dessous) et que le ">" n’est
pas immédiatement précédé d’un "/", alors la balise en est
une de début.<doc><a22><PRIVÉ >< doc > (espace après le "<")<a 22> (le nom contient une espace)<a?22> (le nom contient un caractère défendu "?")<22 > (le nom commence par un chiffre)<" est suivi immédiatement d’un "/", alors
la balise en est une de fin. Le "/"
doit alors être suivi d’un nom XML.</doc > (les blancs avant le ">" sont permis)</a22 ></PRIVÉ>< /doc > (espace après le "<")</ a22> (espace après le "/")</> (aucun nom)<" est suivi immédiatement d’un nom XML et que le
">" est immédiatement précédé d’un "/", alors
la balise est dite auto-fermante.<doc /> (les blancs avant le "/" sont permis)<a22 /><PRIVÉ/>< doc/> (espace après le "<")<a22/ > (espace après le "/")Règles sur les noms XML
Les noms que l’on retrouve dans les balises doivent répondre aux règles sur les noms XML. Un nom XML :
Ainsi, les chaînes de caractères suivantes sont des noms XML bien formés :
été_RÉP.ouia-007แสดงถึง(une suite de lettres thaïes)
alors que celles-ci ne le sont pas :
007(commence par un chiffre)a#b(contient un caractère spécial)ce soir(contient une espace)
Le « : » est permis, mais avec règles particulières, liées aux espaces de noms (Namespaces), qui ne sont pas couverts dans ce premier Tour d’horizon. Évitez donc d’utiliser le « : » dans les noms XML de votre cru, mais sachez qu’on peut en retrouver dans certains documents XML, y compris quelques exemples du cours.
La casse des lettres (minuscule vs majuscule) est significative dans les
noms XML; ainsi, abc est un nom différent de Abc.
Il n’y a pas de limite sur la longueur d’un nom XML.
Nous reviendrons plus tard dans le cours sur le choix des noms XML, mais disons pour l’instant qu’en général, on vise à ce qu’un nom XML soit significatif, et on recherche donc un équilibre entre la longueur et l’expressivité. Il n’est pas rare qu’un nom XML soit formé de mots d’une langue naturelle ou d’abréviations, liés dans le respect des règles de formation des noms XML.
Évidemment, en contexte pédagogique, on utilise souvent des noms XML arbitraires, dénués de sens.
Les éléments sont les blocs de construction de base d’un document XML. D’ailleurs, l’élément-document, qui constitue l’essentiel du document, n’est rien d’autre qu’un élément comme les autres. La seul particularité qui le caractérise est le fait qu’il constitue la totalité du document – sauf pour d’éventuels prologue et épilogue.
Un élément est toujours constitué de caractères consécutifs dans un document XML.
Une des deux formes que peut prendre un élément dans un document XML (y compris l’élément-document) est celle d’un segment du document commençant par une balise de début et se terminant par une balise de fin. Voici un exemple d’élément que l’on pourrait retrouver quelque part dans un document XML :
<a>Ça va très bien.</a>
Le nom XML qui suit le "<" ou le "</" dans les
balises qui délimitent un élément s’appelle l’identificateur générique de
l’élément. L’identificateur générique indique le type de
l’élément, que l’on appelle aussi le nom de l’élément. Les
balises de début et de fin d’un élément doivent comporter le même
identificateur générique, comme c’est le cas dans l’exemple. C’est une des règles du
bien-formé.
L’exemple ci-dessus est un élément dont l’identificateur générique (ou nom ou type
d’élément) est a; on peut aussi dire simplement qu’il s’agit d’« un
élément a ».
Tout élément XML peut servir d’élément-document. Tout élément XML constitue donc en lui-même un document complet, avec prologue et épilogue vides.
Cet état de choses nous permet d’appliquer notre convention de présentation de documents complets à nos exemples d’élément. Chaque exemple d’élément est donc suivi d’un lien vers le fichier source de l’exemple et d’une image montrant le rendu typique en navigateur.
Revoici l’exemple précédent, présenté comme un document complet :
<a>Ça va très bien.</a>Rendu typique en navigateur :
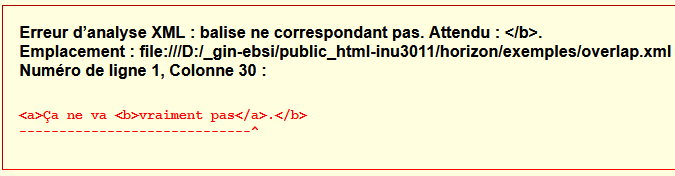
L’élément (et document) suivant est, pour sa part, mal formé, puisque les identificateurs génériques des balises de début et de fin ne coïncident pas :
MAL FORMÉ :
<a>Ça ne va pas du tout.</b>Rendu typique en navigateur :
Notez que, comme la casse des lettres est significative dans les noms d’élément, ceci est aussi mal formé :
MAL FORMÉ :
<a>Ça ne va vraiment pas.</A>
Quand un élément a la forme d’un segment délimité par une balise de début et une balise de fin, ce qui se trouve entre les deux balises s’appelle le contenu de l’élément. Le contenu d’un tel élément est donc égal à l’élément lui-même, moins ses balises de début et de fin.
Le contenu de l’élément suivant :
<a>Ça va très bien.</a>
est donc la chaîne de caractères :
Ça va très bien.
Un des types de contenu que peut avoir un élément est effectivement une chaîne de caractères quelconque (sujette à quelques restrictions, que nous verrons plus loin). Nous verrons aussi ci-dessous qu’un élément peut contenir autre chose qu’une chaîne de caractères.
Les règles du bien-formé ne mettent aucune limite sur la longueur d’une chaîne de caractères contenue dans un élément.
Il est possible que les balises de début et de fin qui délimitent l’élément « se touchent », comme dans cet exemple :
<doc></doc>
Cette situation est permise par les règles du bien-formé. Le contenu de l’élément est alors la chaîne vide et on dit que son contenu est vide. Par extension, on dit aussi que l’élément lui-même est vide.
La seconde des formes que peut prendre un élément XML (la première étant celle d’un segment délimité par une balise de début et une balise de fin) est celle d’une balise auto-fermante. C’est le seul cas en XML où un élément coïncide avec une balise.
Une balise auto-fermante n’a pas besoin de balise de fin correspondante; elle se « suffit à elle-même ». On pourrait dire qu’elle est sa propre balise de fin. Une balise auto-fermante est en fait une abréviation pour une balise de début suivie immédiatement d’une balise de fin munie du même identificateur générique. C’est donc une façon compacte de représenter un élément vide. Ainsi, cet élément :
<doc/>Rendu typique en navigateur :
est rigoureusement équivalent à :
<doc></doc>Rendu typique en navigateur :
Comme vous pouvez voir, dans son rendu, le navigateur Web ramène de son propre chef les deux balises qui se touchent à une balise auto-fermante : légitime, puisque les deux formes sont rigoureusement équivalentes. Vous pouvez faire afficher la source pour vérifier que le document XML contient bel et bien les deux balises séparées.
Même s’il peut être difficile à ce stade-ci d’imaginer qu’un élément vide puisse
avoir quelque utilité que ce soit pour véhiculer de l’information, ils sont en fait
fort utiles en XML, par exemple pour véhiculer des informations typiquement
représentées par une simple mention, dont la seule présence est porteuse de sens,
comme « Confidentiel », « Brouillon » ou « Annulé ». Ces mentions sont naturellement
représentées en XML par des éléments vides sous la forme de balises auto-fermantes :
<Confidentiel />, <Brouillon />,
<Annulé />.
Puisqu’elle est à elle seule un élément XML et que tout élément XML peut constituer l’élément-document d’un document XML (à prologue et épilogue vides), une balise auto-fermante peut constituer à elle seule un document XML complet. À titre anecdotique, notons que, techniquement, le document XML bien formé le plus court possible est constitué de quatre caractères et a la forme :
<a/>Rendu typique en navigateur :
N’importe quelle lettre pourrait bien sûr être utilisée au lieu de
a.
Outre du texte, un élément peut contenir d’autres éléments, qui lui sont alors imbriqués. Ces éléments imbriqués sont appelés sous-éléments de l’élément qui les contient. L’exemple suivant, que nous avons déjà rencontré précédemment, illustre cette situation :
<liste>Voici deux items:<item>1</item><item>2</item></liste>Rendu typique en navigateur :
L’élément liste contient ici deux sous-éléments item, en
plus de la chaîne de caractères "Voici deux items:".
Les deux sous-éléments sont ici mis en évidence, le premier par soulignement simple, le second par soulignement double :
<liste>Voici deux items:<item>1</item><item>2</item></liste>
Notons que l’imbrication des éléments ne peut pas être partielle; autrement dit, les chevauchements de deux éléments sont interdits. Ainsi, ceci est mal formé :
MAL FORMÉ:
<a>Ça ne va <b>vraiment pas</a>.</b>Rendu typique en navigateur :
Notons aussi que la possibilité d’imbrication n’a rien à voir avec les noms
d’élément. En XML bien formé, les éléments peuvent être imbriqués n’importe comment,
peu importe le nom qu’ils portent. Le document suivant est tout aussi bien formé que
celui qui utilisait les noms liste et item :
<rien>Voici deux items:<rien>1</rien><rien>2</rien></rien>Rendu typique en navigateur :
L’imbrication des éléments dans un document XML n’est pas limitée à un niveau, mais peut être arbitrairement profonde. Le document suivant comporte trois niveaux d’imbrication :
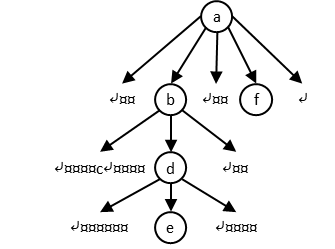
<a><b><c/><d><e/></d></b><f/></a>Rendu typique en navigateur :
Le terme structure hiérarchique d’un document XML renvoie à la structure d’imbrication des différents éléments dans le document. Comme l’exemple le démontre clairement, cette structure d’imbrication n’est pas nécessairement mise en évidence dans le code source du document. Néanmoins, elle est entièrement déterminée par l’agencement des différentes balises présentes dans le document.
Tel que mentionné précédemment, l’interprétation faite par le navigateur vise à rendre explicite la structure hiérarchique du document, indépendamment de la façon dont les éléments sont disposés dans le code source.
Bonne pratique à la saisie de documents
Même si ce n’est pas nécessaire, une bonne pratique consiste à disposer le code source d’un document XML en utilisant les sauts de ligne et les indentations de façon à ce que l’imbrication des éléments soit mise en évidence.
Ainsi, on aurait tout intérêt à structurer le code source de l’exemple précédent ainsi :
<a>
<b>
<c/>
<d>
<e/>
</d>
</b>
<f/>
</a>
c’est-à-dire, si on rend visibles les espaces et sauts de ligne :
<a>⤶
¤¤<b>⤶
¤¤¤¤<c/>⤶
¤¤¤¤<d>⤶
¤¤¤¤¤¤<e/>⤶
¤¤¤¤</d>⤶
¤¤</b>⤶
¤¤<f/>⤶
</a>Rendu typique en navigateur :
Le rendu en navigateur ne change pas, mais le code source est beaucoup plus lisible pour l’œil humain.
La mise en évidence de la structure hiérarchique d’un document est tellement importante pour la lisibilité humaine, qu’oXygen possède une fonction spécialement pour réaliser cette opération. Vous pouvez l’expérimenter en ouvrant dans oXygen le premier exemple de cette section (celui sur une seule ligne), puis en faisant :
Document → Source → Formater et indenter
Le code source sera instantanément redisposé comme ci-dessus. Ce type de fonction s’appelle pretty-printing dans le monde de l’informatique.
Rappelons que le contenu d’un élément est ce qui se trouve entre ses balises de début et de fin; autrement dit, c’est ce qu’il reste de l’élément une fois retirées ses balises de début et de fin.
Le contenu textuel direct d’un élément est ce qui reste de son contenu si on en retire les sous-éléments. Prenons un des derniers exemples :
<liste>Voici deux items:<item>1</item><item>2</item></liste>
Si on retire du contenu de liste les sous-éléments :
<liste>Voici deux items:<item>1</item><item>2</item></liste>
il nous reste la chaîne de caractères :
Voici deux items:
Cette chaîne est donc le contenu textuel direct de l’élément
liste.
Notons que les chaînes vides situées entre deux balises consécutives ne sont pas
retenues comme faisant partie du contenu textuel direct. Ainsi, dans l’exemple
précédent, les chaînes vides entre les deux item et entre le second
item et la balise de fin </liste> ne sont pas
considérées.
Similairement, un élément vide est considéré comme n’ayant aucun contenu textuel direct (même si son contenu comme tel est la chaîne vide).
Notons que le contenu textuel direct d’un élément peut être constitué de plus d’une chaîne de caractères. Avec l’exemple suivant :
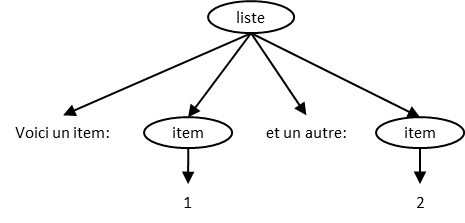
<liste>Voici un item:<item>1</item>et un autre:<item>2</item></liste>Rendu typique en navigateur :
l’élimination des sous-éléments :
<liste>Voici un item:<item>1</item>et un autre:<item>2</item></liste>
laisse comme contenu textuel direct de liste les deux chaînes de
caractères suivantes :
Voici un item:
et un autre:
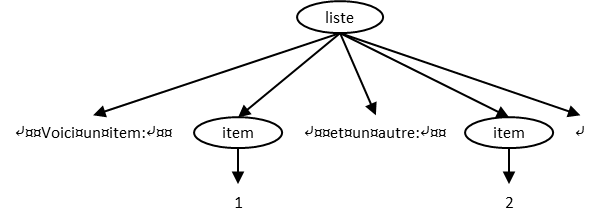
Notons que si on introduit des sauts de ligne, espaces ou autres blancs dans un document, le contenu textuel direct de certains éléments sera modifié. Par exemple, si on « aère » le dernier exemple de façon à mettre en évidence l’imbrication des éléments :
<liste>⤶
¤¤Voici¤un¤item:⤶
¤¤<item>1</item>⤶
¤¤et¤un¤autre:⤶
¤¤<item>2</item>⤶
</liste>Rendu typique en navigateur :
le contenu textuel direct de liste devient une suite de trois chaînes
de caractères :
⤶¤¤Voici¤un¤item:⤶¤¤
⤶¤¤et¤un¤autre:⤶¤¤
⤶
Notons que la troisième de ces chaînes n’est constituée que d’un blanc, en l’occurrence, un saut de ligne (⤶). Notons aussi que nous représentons les sauts de ligne par le symbole ⤶, selon nos conventions typographiques, mais sans le faire suivre visuellement d’un changement de ligne, ceci dans un but d’allègement.
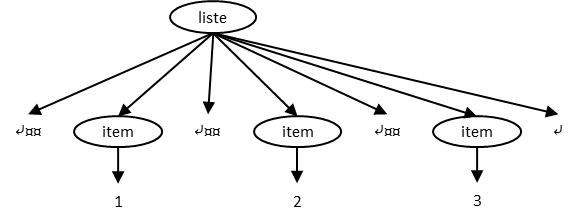
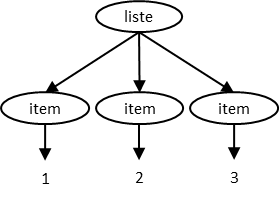
Il est possible que le contenu textuel direct d’un élément soit inexistant, même si
l’élément n’est pas vide. C’est le cas de l’élément liste suivant :
<liste><item>1</item><item>2</item><item>3</item></liste>Rendu typique en navigateur :
Après retrait des sous-éléments, le contenu est vide :
<liste><item>1</item><item>2</item><item>3</item></liste>
Comme les chaînes vides ne sont pas considérées comme contenu textuel direct, on conclut que l’élément n’a aucun contenu textuel direct.
Il est utile de qualifier les éléments XML en fonction du genre de contenu qu’ils possèdent.
Éléments vides
Tel que vu précédemment, un élément vide est un élément dont les balises de début et de fin « se touchent », ou encore représenté par une balise auto-fermante.
Éléments textuels
Un élément textuel est un élément qui n’est pas vide et qui ne contient aucun sous-élément imbriqué. Le contenu d’un élément textuel est forcément une simple chaîne de caractères non vide.
Éléments-conteneurs
Un élément-conteneur – ou simplement conteneur – est un élément qui contient au moins un sous-élément imbriqué et dont le contenu textuel direct est inexistant ou ne comporte que des chaînes constituées exclusivement de blancs.
L’élément liste du dernier exemple ci-dessus est un conteneur :
<liste><item>1</item><item>2</item><item>3</item></liste>
En effet, il contient au moins un sous-élément et n’a aucun contenu textuel direct.
Si on « aère » le contenu de l’élément liste pour mettre en évidence
l’imbrication des sous-éléments, l’élément demeure un conteneur :
<liste>
<item>1</item>
<item>2</item>
<item>3</item>
</liste>Rendu typique en navigateur :
En effet, le contenu textuel direct de liste est une suite de chaînes
constituées exclusivement de blancs :
⤶¤¤
⤶¤¤
⤶¤¤
⤶
Notons au passage que dans les deux exemples, les sous-éléments (item)
sont quant à eux des éléments textuels.
Éléments mixtes
Un élément mixte est un élément qui possède les deux caractéristiques suivantes :
On dit aussi que l’élément a un contenu mixte.
Les exemples suivants, déjà présentés ci-dessus, illustrent chacun un élément mixte :
<liste>Voici un item:<item>1</item>et un autre:<item>2</item></liste>Rendu typique en navigateur :
et :
<liste>⤶
¤¤Voici¤un¤item:⤶
¤¤<item>1</item>⤶
¤¤et¤un¤autre:⤶
¤¤<item>2</item>⤶
</liste>Rendu typique en navigateur :
Dans les deux cas, l’élément liste contient au moins un sous-élément
(en fait, il en contient deux) et possède un contenu textuel direct comportant au
moins une chaîne contenant au moins un caractère non blanc. En effet, tel que vu
précédemment, le contenu textuel direct de liste dans le premier
exemple comporte les deux chaînes suivantes :
Voici un item:
et un autre:
et dans le deuxième exemple, il comporte les trois chaînes suivantes :
⤶¤¤Voici¤un¤item:⤶¤¤
⤶¤¤et¤un¤autre:⤶¤¤
⤶
Le contenu de n’importe quel élément se divise donc naturellement en une succession d’unités de contenu, qui sont chacune soit une chaîne de caractères non vide (faisant partie du contenu textuel direct de l’élément), soit un sous-élément.
Un élément vide n’a aucune unité de contenu.
Un élément textuel a exactement une unité de contenu, qui est l’unique chaîne de caractères que l’élément contient.
Un élément-conteneur ou mixte a un nombre variable (mais plus grand que zéro) d’unités de contenu, chacune étant soit une des chaînes du contenu textuel direct de l’élément, soit un sous-élément.
Les unités de contenu d’un élément sont naturellement ordonnées selon leur ordre d’apparition dans le contenu de l’élément.
Voici la liste ordonnée des unités de contenu de l’élément liste dans
le dernier exemple d’élément mixte ci-dessus :
- La chaîne
⤶¤¤Voici¤un¤item:⤶¤¤- Le sous-élément
<item>1</item>- La chaîne
⤶¤¤et¤un¤autre:⤶¤¤- Le sous-élément
<item>2</item>- La chaîne
⤶
Cet élément liste possède donc cinq unités de contenu.
Une unité de contenu qui est une chaîne de caractères est dite unité textuelle.
Le contenu textuel d’un élément (ne pas confondre avec le contenu textuel direct) est ce qui reste du contenu de l’élément une fois retirées toutes les balises qu’il contient, s’il y en a. Si un élément ne contient aucun sous-élément, son contenu textuel est identique à son contenu, mais s’il contient au moins un sous-élément, il est différent.
Reprenant deux des exemples précédents, nous soulignons ici le contenu textuel de chacun :
<saga>Très longue histoire.</a>Rendu typique en navigateur :
<liste>Voici deux items:<item>1</item><item>2</item></liste>Rendu typique en navigateur :
Dans le premier cas, le contenu textuel est identique au contenu de l’élément, alors que dans le second, les balises des sous-éléments sont exclues. Le contenu textuel est donc la chaîne :
Voici deux items:12
Notez que, lorsqu’il y a un ou des sous-éléments, un même caractère peut faire
partie du contenu textuel de plusieurs éléments. Ainsi, dans l’exemple précédent, le
caractère 1 fait partie du contenu textuel du premier élément
item, mais également de celui de l’élément-document
liste.
Tout ce qui n’est pas le contenu textuel d’un élément est appelé le balisage de cet élément. Le balisage inclut les balises de l’élément lui-même et toutes celles qui pourraient se trouver dans son contenu.
Le contenu textuel d’un élément peut être vide même si l’élément lui-même n’est pas
vide. L’élément c qui suit n’est pas vide, mais, n’étant constitué que
de balises, il a un contenu textuel vide :
<c><a/><b/></c>Rendu typique en navigateur :
Notons au passage que cet élément (c) n’a aucun contenu textuel
direct, puisque les chaînes vides ne sont pas « comptées » dans le contenu textuel
direct.
Les notions de contenu textuel, de contenu textuel direct et de balisage sont définies pour des éléments, mais on peut aussi les appliquer à un document complet, sous-entendant alors qu’elles s’appliquent à l’élément-document.
Une des façons les plus intuitives de mettre en évidence la structure d’imbrication des éléments dans un document XML est de représenter le document sous la forme d’un arbre inversé. Ce type de représentation est particulièrement important, car il justifie une terminologie généalogique (enfant, parent, ancêtre, etc.) qui s’avère fort utile pour décrire le positionnement relatif des éléments dans un document XML. De plus, la plupart des langages de traitement de documents XML utilisent cette terminologie, notamment XPath et XSLT, que nous verrons plus tard dans le cours.
Dans la représentation en arbre inversée, chaque élément du document (y compris
l’élément-document) est représenté par un ovale dans lequel on inscrit son
identificateur générique. Par exemple, pour un élément liste, on
trace :
Si l’élément est vide, la représentation de l’élément se résume à
cet ovale. Par exemple, pour l’élément vide <liste/>, l’arbre
inversé complet se résume à l’ovale ci-dessus.
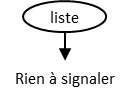
Si l’élément est textuel, la chaîne constituant l’unique unité de
contenu est simplement placée telle quelle dans l’arbre inversé, sous l’élément,
reliée à lui par une flèche descendante. Par exemple, l’élément textuel
<liste>Rien à signaler</liste> se représente ainsi :
Si l’élément est un conteneur ou mixte, les unités de contenu sont disposées sous l’élément dans leur ordre d’apparition, chacune reliée à l’élément par une flèche descendante. Les unités de contenu qui sont des chaînes de caractères sont placées telles quelles dans l’arbre inversé, alors que les sous-éléments sont traités par l’application récursive des règles ci-dessus.
Ainsi, notre dernier exemple d’élément mixte ci-dessus :
<liste>⤶
¤¤Voici¤un¤item:⤶
¤¤<item>1</item>⤶
¤¤et¤un¤autre:⤶
¤¤<item>2</item>⤶
</liste>Rendu typique en navigateur :
est représenté comme suit :
Les sous-éléments item sont des éléments textuels et ont donc été
traités récursivement en appliquant la règle pour les éléments textuels.
La représentation d’un document complet est celle de son élément-document. Ainsi,
si l’élément liste de l’exemple constitue un document complet, l’arbre
inversé de ce document est celui que nous venons de donner.
L’appellation « arbre inversé » vient du fait que l’élément-document peut être vu comme la racine d’un arbre inversé (tête en bas), dont les « branches » sont les flèches et les « feuilles », les unités textuelles et les éléments vides du document.
Tout ce qui n’est pas une flèche s’appelle un nœud. La racine et toutes les unités de contenu sont donc des nœuds, y compris les feuilles. Un nœud correspondant à une unité textuelle est dit nœud textuel. Tous les autres nœuds, y compris la racine, sont dits nœuds-éléments ou, quand le contexte ne porte pas à confusion, simplement éléments.
Les termes arbre, nœud, racine et feuille viennent de la théorie des graphes en mathématique, où il sont parfois définis de façon légèrement différente.
C’est la représentation en arbre inversé qui justifie les deux autres noms utilisés pour désigner l’élément-document : l’élément-racine et l’élément de plus haut niveau (EPHN), puisqu’il occupe le niveau le plus élevé dans l’arbre inversé.
Allègements courants
La représentation en arbre inversé est un outil pour l’humain et non pour la machine. Il est donc courant que l’on se permette certains allègements pour en faciliter la confection et/ou la lecture.
Les allègements les plus fréquents sont :
Voici un item:" au lieu de
"⤶¤¤Voici¤un¤item:⤶".Jean Valjean" au lieu de
"Jean⤶¤¤¤¤Valjean"⤶¤¤".Un arbre inversé qui intègre ces allègements est dit allégé (ou simplifié).
Ces allègements sont particulièrement « payants » lorsqu’on travaille avec un document dont le code source a été « aéré » pour mettre en évidence la structure d’imbrication des éléments. Par exemple, l’arbre allégé de l’exemple précédent est sensiblement plus facile à lire que sans allègement :
Similairement pour l’exemple suivant (déjà présenté ci-dessus) :
<liste>
<item>1</item>
<item>2</item>
<item>3</item>
</liste>Rendu typique en navigateur :
dont la représentation sans allègement est :
alors qu’avec les allègements, elle se résume à :
La représentation d’un document sous forme d’arbre inversé permet notamment d’utiliser des termes généalogiques comme parent, enfant et descendant pour situer les éléments et les unités textuelles les uns par rapport aux autres.
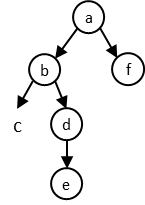
Soit le document suivant (variation sur un des exemples ci-dessus) :
<a> <b> c <d> <e/> </d> </b> <f/> </a>Rendu typique en navigateur :
L’arbre inversé allégé du document est :
Un seul des nœuds est textuel : c. Les autres sont des nœuds-éléments.
Les lettres a à f désigneront les nœuds correspondants
dans l’arbre.
Enfants, parents
Les nœuds qui correspondent aux unités de contenu d’un nœud-élément sont appelés enfants du nœud-élément.
Ainsi :
b et f sont enfants de a.c et d sont enfants de b.e est enfant de d.Inversement :
a est le parent de b et
f.b est le parent de c et d.d est le parent de e.Par la façon dont l’arbre est construit, tous les nœuds ont exactement un parent, sauf la racine qui n’en a aucun.
Un sous-élément, tel que défini précédemment, est simplement un enfant qui est lui-même un nœud-élément.
L’imbrication d’un enfant dans un parent est parfois qualifiée de directe ou immédiate.
Descendants, ancêtres
Tous les nœuds que l’on peut atteindre en parcourant les flèches de l’arbre à partir d’un certain nœud sont appelés les descendants de ce nœud. Les descendants d’un nœud incluent donc ses enfants. Un nœud n’est pas considéré comme son propre descendant.
Ainsi :
b, c, d, e et f
sont tous descendants de a.c, d et e sont descendants de
b.e est descendant de d.Inversement :
a est ancêtre de b, c,
d, e et f.b est ancêtre de c, d et
e.d est ancêtre de e.Sauf la racine, qui n’a aucun ancêtre, les ancêtres d’un nœud incluent toujours son parent et la racine de l’arbre (qui sont parfois le même nœud).
L’imbrication dans un parent d’un descendant qui n’est pas aussi son enfant est parfois qualifiée d’indirecte.
Frères
Les nœuds qui ont le même parent sont des frères (en
anglais, siblings). Ainsi, b et f sont frères,
comme le sont c et d. De deux frères, celui qui arrive en
premier dans le document (donc, le plus à gauche dans l’arbre) est dit
l’aîné; l’autre est dit le cadet. Ainsi, b est
frère aîné de f et d est frère cadet de
c.
Exercice : Tracez l’arbre inversé non allégé du document. Considérez que le document – avec les blancs mis en évidence – est comme suit :
<a>⤶ ¤¤<b>⤶ ¤¤¤¤c⤶ ¤¤¤¤<d>⤶ ¤¤¤¤¤¤<e/>⤶ ¤¤¤¤</d>⤶ ¤¤</b>⤶ ¤¤<f/>⤶ </a>
Nous avons déjà dit que n’importe quel élément XML peut constituer l’élément-document d’un document XML et donc constituer à lui seul un document XML complet. Ce qu’il reste à préciser, c’est que la section « élément-document » d’un document XML ne peut pas être autre chose qu’un seul et unique élément XML. Autrement dit, la seule section obligatoire d’un document XML est toujours et obligatoirement un et un seul élément XML.
Évidemment, un document XML peut contenir d’autres éléments que l’élément-document, cependant, ceux-ci doivent être des descendants de l’élément-document. Tous les éléments dans un document XML doivent être imbriqués, directement ou indirectement, dans l’élément-document; ils ne peuvent pas être « à côté » de celui-ci. Ainsi, le document suivant est mal formé :
MAL FORMÉ:
<a/><b/>Rendu typique en navigateur :
puisqu’il n’y a pas un seul élément de plus haut niveau, mais deux, qui sont « côte-à-côte ». En contraste, le document suivant (déjà rencontré ci-dessus) est bien formé :
<c><a/><b/></c>Rendu typique en navigateur :
puisqu’il consiste en un unique élément (c) qui, lui, contient les
deux frères a et b.
Jusqu’ici, les exemples de document XML ont été plutôt scolaires et n’étaient pas très réalistes en termes de contenu informationnel. Nous concluons cette section avec un exemple un peu plus réaliste, quoique encore très court, de document XML complet :
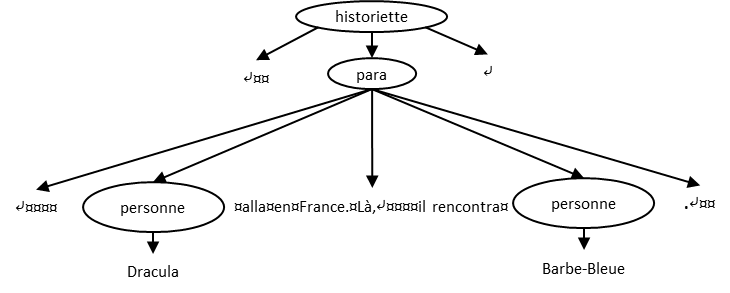
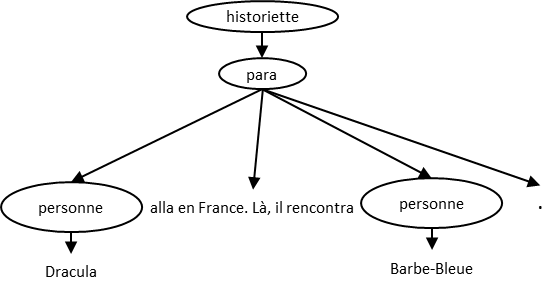
<historiette>
<para>
<personne>Dracula</personne> alla en France. Là,
il rencontra <personne>Barbe-Bleue</personne>.
</para>
</historiette>Rendu typique en navigateur :
L’arbre inversé non allégé de ce document est :
L’arbre allégé, quant à lui est :
Ainsi :
para a cinq enfants dans l’arbre non allégé, mais seulement
quatre dans l’arbre allégé.<personne>Barbe-Bleue</personne> est frère cadet de
<personne>Dracula</personne>.para dans l’arbre allégé est
<personne>Dracula</personne> et le cadet, le nœud textuel
".".Il y a certaines restrictions sur ce qui peut se retrouver dans le contenu textuel d’un élément.
Comme le caractère < signale le début d’une balise, on ne peut pas
l’inscrire tel quel dans le contenu textuel d’un élément. Il faut plutôt inscrire la
suite de quatre caractères « < » qui, par convention
en XML, représente le caractère <
comme contenu textuel, et non comme délimiteur de balise. Les applications
qui traitent le XML connaissent la convention et font la substitution appropriée au
moment de traiter le document.
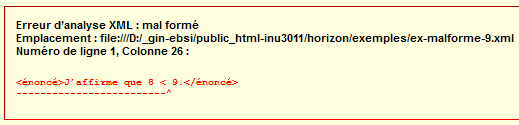
Par exemple, le document suivant serait mal formé :
MAL FORMÉ:
<énoncé>J’affirme que 8 < 9.</énoncé>Rendu typique en navigateur :
alors que celui-ci est bien formé :
<énoncé>J’affirme que 8 < 9.</énoncé>Rendu typique en navigateur :
Son contenu textuel est la chaîne J’affirme que 8 < 9., que les
applications XML (dont les navigateurs Web) interprètent comme :
J’affirme que 8 < 9.
La suite de caractères « < » est ce qu’on appelle un appel
d’entité prédéfinie. C’est une des formes d’un type de construction plus
général qui utilise les caractères & (esperluette) et le
point-virgule comme délimiteurs. À cause de ce rôle de délimiteur, l’esperluette se
retrouve dans le même cas que le <, en ce sens qu’elle ne peut pas
être inscrite telle quelle dans le contenu textuel d’un élément.
Si l’on veut inscrire le caractère & dans le contenu textuel d’un
élément, il faut en fait inscrire « & », qui est un
autre appel d’entité prédéfinie représentant, par convention, le caractère
&
comme contenu textuel.
Ainsi donc, le contenu textuel du document :
<sélection>prix > 5$ & < 10$</sélection>
est interprété comme la chaîne :
prix > 5$ & < 10$Rendu typique en navigateur :
Une autre restriction, qui ne s’explique que par des raisons
techniques et historiques, est que l’on ne doit pas retrouver la suite de trois
caractères ]]> dans le contenu textuel d’un élément.
Nous en verrons un peu plus sur les appels d’entité prédéfinie dans un texte distinct.
En plus d’un nom d’élément, une balise de début ou une balise auto-fermante peut aussi contenir une spécification d’attribut ou plus. Une balise de fin ne peut pas contenir de spécification d’attribut.
Les spécifications d’attribut, si présentes, sont séparées du nom d’élément (et l’une de l’autre lorsqu’il y en a plusieurs) par un blanc ou plus. Elles ont toujours une des formes :
nom-d’attribut = "valeur-d’attribut"
ou
nom-d’attribut = 'valeur-d’attribut'
La valeur d’attribut est donc toujours délimitée, soit par des
guillemets simples, soit par des doubles. Le même type de guillemet doit être
utilisé pour délimiter le début et la fin d’une même valeur d’attribut. Les blancs
avant et après le signe = sont facultatifs.
Il n’y a pas de limite sur la longueur d’une valeur d’attribut.
Les noms d’attribut doivent satisfaire, comme les noms d’élément, aux règles sur les noms XML.
Un attribut est en général utilisé pour consigner des informations qui complètent ou qualifient celle véhiculée par l’élément auquel il s’applique, c’est-à-dire, l’élément auquel appartient la balise dans laquelle l’attribut est spécifié.
Notons que, comme les spécifications d’attribut sont incluses à l’intérieur de la balise de début d’un élément (ou de sa balise auto-fermante), et que le contenu textuel d’un élément exclut toute balise, ni les noms ni les valeurs d’attribut ne font partie du contenu textuel de l’élément.
Voici quelques exemples de balises (de début ou auto-fermantes) bien formées incluant une ou des spécifications d’attribut :
<NOM COURRIEL="sp@picard.com" >
<ligne n = "2" type="phrase">
<conf niveau="1a"/>
<infos typAdr ='civique' NIV = "***" p= ' 45,67$ @ 5% ' />
Assurez-vous que vous pouvez mentalement bien identifier dans chacun de ces exemples le nom d’élément, ainsi que le nom et la valeur de chaque attribut spécifié dans la balise.
L’ordre des spécifications d’attribut à l’intérieur d’une balise est toujours arbitraire et n’est jamais significatif. Ainsi :
<ligne n="2" type="phrase">
est toujours rigoureusement équivalent à :
<ligne type="phrase" n='2'>
Le même attribut ne peut pas être spécifié plus d’une fois à l’intérieur de la même balise. Ainsi, les balises suivantes sont mal formées, et donc en erreur :
MAL FORMÉ:
<épicerie item="sucre" item="café">MAL FORMÉ:
<rés mc = 'bon' rép="42" mc="passable" />
Comme la casse des lettres est significative dans les noms d’attribut,
a et A désignent deux attributs différents et donc ceci
est bien formé :
<e a="2" A="3">Ça va.</e>Rendu typique en navigateur :
Une valeur d’attribut est simplement une suite de caractères quelconques, qui peut
inclure des lettres, des chiffres, des espaces et des caractères
spéciaux, à l’exception des caractères « < » et
« & », qui, comme dans le contenu textuel d’un élément, doivent
toujours et obligatoirement être représentés par les appels d’entité prédéfinie
« < » et « & ». Ainsi, si l’on voulait
spécifier la chaîne :
prix > 5$ & < 10$
comme valeur d’attribut, il faudrait inscrire plutôt prix > 5$ &
< 10$ entre les guillemets, par exemple :
<sélection test='prix > 5$ & < 10$' />Rendu typique en navigateur :
Notons qu’il n’est pas une erreur d’utiliser comme nom d’un attribut le même nom que celui de l’élément auquel il s’applique. Ainsi, l’exemple suivant est bien formé :
<sexe sexe="F" />Rendu typique en navigateur :
Il n’y a pas de limite sur le nombre de spécifications d’attribut qu’une balise de début ou auto-fermante peut comporter.
Notons que le fait qu’un élément vide soit porteur d’attributs ou non n’a aucune influence sur sa qualité d’élément vide. Un élément vide demeure un élément vide, même s’il possède un ou plusieurs attributs. Le qualificatif « vide » s’applique au contenu de l’élément et non à sa ou ses balises.
Les attributs constituent une façon de véhiculer de l’information différente du contenu des éléments. Chaque façon a ses caractéristiques et limites propres. Certaines informations se représentent mieux comme une valeur d’attribut et d’autres comme contenu d’un élément. Nous reviendrons sur cette question dans la partie du cours portant sur la modélisation.
Les commentaires sont un type de construction syntaxique que l’on pourrait facilement omettre dans un premier tour d’horizon de XML, mais qui est tellement pratique et répandu que nous le présentons quand même.
Un commentaire est un passage délimité au début par <!--
et à la fin par -->. Le contenu du commentaire, c’est-à-dire
ce qui est situé entre ces délimiteurs, peut être quelconque; il n’a pas à respecter
une forme particulière, sinon que, pour une raison historique, il ne peut pas
contenir deux tirets de suite (--).
On peut retrouver des commentaires dans un document partout où on peut trouver du contenu textuel (c’est-à-dire n’importe où, sauf imbriqués à l’intérieur d’une balise). Voici un exemple de document avec un commentaire :
<naissance>22 janvier <!--1986--> à Montréal</naissance>Rendu typique en navigateur :
Théoriquement, un commentaire doit être ignoré par les applications qui traitent le XML, dans le sens qu’elles doivent se comporter comme s’il n’était pas là. Comme on peut voir avec l’exemple précédent, cependant, certaines applications ne les ignorent pas complètement, notamment les navigateurs Web, qui les affichent quand même, mais avec un formatage permettant de les distinguer du contenu textuel avoisinant.
Les commentaires doivent être exclus lorsqu’on établit le contenu textuel ou le contenu textuel direct d’un élément, ou pour déterminer si un élément a un contenu mixte. Ainsi, le contenu textuel de l’élément dans l’exemple précédent se résume aux parties soulignées ci-dessous :
<naissance>22 janvier <!--1986--> à Montréal</naissance>
Une des utilisations fréquentes des commentaires est pour « désactiver » temporairement une partie du contenu d’un élément sans l’éliminer complètement, de façon à pouvoir la réactiver ultérieurement si désiré. Typiquement, la partie ainsi « cachée » serait un sous-élément si elle n’était pas mise en commentaire. Ainsi, dans cet exemple :
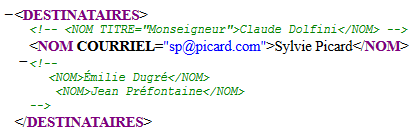
<DESTINATAIRES>
<!-- <NOM TITRE="Monseigneur">Claude Dolfini</NOM> -->
<NOM COURRIEL="sp@picard.com">Sylvie Picard</NOM>
<!-- <NOM>Émilie Dugré</NOM>
<NOM>Jean Préfontaine</NOM> -->
</DESTINATAIRES>Rendu typique en navigateur :
l’élément DESTINATAIRES ne contient qu’un seul sous-élément, puisque
les autres passages qui « ressemblent » à des sous-éléments sont inclus dans des
commentaires et ne sont donc pas des sous-éléments.
Même si, jusqu’à maintenant, nous ne nous sommes intéressés qu’aux cas où le prologue et l’épilogue d’un fichier XML sont vides, il convient de mentionner qu’en fait, on peut y retrouver des commentaires, lesquels, comme lorsqu’ils surviennent dans un élément, sont simplement destinés à être ignorés par les applications.
Pendant qu’on est sur le sujet du prologue et de l’épilogue, disons qu’en plus des commentaires, on peut aussi y retrouver des blancs (espaces, sauts de ligne, etc.), qui sont eux aussi destinés à être ignorés par les applications.
Nous verrons, dans le texte portant sur la validité d’un document XML, que le prologue peut aussi contenir une déclaration de type de document.
Finalement, nous verrons en classe que le prologue peut également contenir une déclaration XML et un lien vers une feuille de style, qui ne sont pas présentés dans ce premier Tour d’horizon.
Voici, en vrac, les aspects de XML (ou souvent considérés comme en faisant partie) non couverts dans ce Premier tour d’horizon :
PUBLIC.CDATA.INCLUDE, IGNORE.NDATA.NOTATION.ID, IDREF, IDREFS,
ENTITY, ENTITIES, NMTOKENS.ANY.Certains de ces points (mais pas tous) seront traités ultérieurement dans le cours.

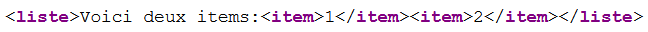
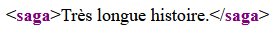
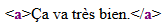


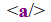

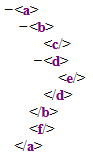


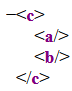

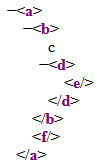

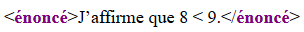
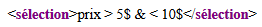
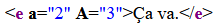
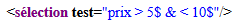
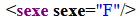

{kind=link}