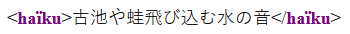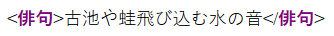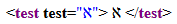<phrase attrib="x > y">
"1 > 2?
C'est tout et n'importe quoi!",
dit-il.
</phrase>
Rendu typique en navigateur : 
Copyright © 2005-2023 Yves MARCOUX; dernière modification de cette page : 2023-01-16.
INU3011 Documents structurés – Premier Tour d’horizon de XML
Index de ce texte — Index général du Tour d’horizon — Accueil du Tour d’horizon
Yves MARCOUX - EBSI - Université de Montréal
De façon générale, le mécanisme des entités en XML permet à certains
« morceaux » de contenu d’être représentés par des « abréviations », appelées
appels d’entité, plutôt que d’être inscrits directement dans un document.
Nous avons déjà rencontré dans un texte précédent deux appels d’entité
prédéfinie : < et &, représentant
respectivement les caractères < et &. Dans le
présent texte, nous parlerons plus en détail des entités prédéfinies, et
introduirons également les entités caractère.
Mentionnons qu’il existe en XML trois autres types d’entités que nous ne voyons pas dans ce texte : les entités générales, les entités paramètres et les entités non analysées.
Les deux seuls caractères qui ne peuvent jamais être inscrits directement dans le
contenu textuel d’un élément ou dans une valeur d’attribut sont le plus-petit-que
< et l’esperluette &. Mais en réalité, XML
possède cinq entités prédéfinies, avec chacune
son appel correspondant :
| Appel | Nom complet | Caractère représenté |
|---|---|---|
< |
lower than | < |
& |
ampersand (en français, esperluette) | & |
> |
greater than | > |
' |
apostrophe | ' |
" |
quotation mark | " |
Les deux seules vraiment nécessaires sont les deux premières, puisque dans le
contenu textuel d’un élément ou dans une valeur d’attribut, les caractères
< et & doivent toujours obligatoirement
être représentés par < ou &.
Les trois dernières existent plus par commodité que par nécessité, puisque les
caractères >, ' et " peuvent, comme tous les
autres caractères Unicode, être inscrits directement dans le contenu textuel d’un
élément ou dans une valeur d’attribut. Les seuls cas où
' et " peuvent être nécessaires sont
lorsqu’on doit inscrire une valeur d’attribut contenant à la fois un
' et un ". En effet, l’un ou l’autre doit
obligatoirement être utilisé comme délimiteur à gauche et à droite de la valeur
d’attribut, et serait donc incorrectement interprété comme signalant la fin de la
valeur d’attribut si on l’inscrivait comme tel dans la valeur d’attribut. Quant à
>, il ne s’agit réellement que d’une
commodité.
Même s’il ne s’agit que de commodités, les appels d’entité >,
' et " peuvent être utilisés en tout
temps. Ainsi, on peut écrire :
<phrase attrib="x > y">
"1 > 2? C'est tout et n'importe quoi!", dit-il.
</phrase>Rendu typique en navigateur :
Mais ce qui suit serait tout aussi bien formé (et tout à fait équivalent) :
<phrase attrib="x > y">
"1 > 2? C'est tout et n'importe quoi!", dit-il.
</phrase>Rendu typique en navigateur :
On peut même entremêler les caractères >, ' et
" et les appels correspondants >,
' et " de façon complètement
arbitraire dans un même élément ou valeur d’attribut; on pourrait donc tout à fait
récrire ainsi l’exemple précédent :
<phrase attrib="x > y">
"1 > 2? C'est tout et n'importe quoi!", dit-il.
</phrase>Rendu typique en navigateur :
Il n’y a aucun bénéfice à une telle pratique, mais elle n’est pas interdite.
En contraste, ce qui suit est mal formé (triplement : à cause du <
dans la valeur d’attribut, et du < et de l’& dans
le contenu textuel) :
MAL FORMÉ :
<phrase attrib="x < y">
"2 < 1? C'est tout & n'importe quoi!", dit-il.
</phrase>
et devrait absolument être récrit avec les appels d’entité prédéfinie
< et & :
<phrase attrib="x < y">
"2 < 1? C'est tout & n'importe quoi!", dit-il.
</phrase>Rendu typique en navigateur :
À part le plus-petit-que < et l’esperluette &,
tous les caractères du répertoire Unicode peuvent être inscrits directement dans le
contenu textuel d’un élément ou dans une valeur d’attribut. Ainsi, si l’on doit
inscrire un passage en grec, en russe, en chinois ou en arabe, la solution la plus
simple est d’inscrire directement les caractères appropriés, puisque Unicode inclut
tous les alphabets requis. Voici par exemple un des haïkus japonais les plus connus
inscrit directement en japonais comme contenu textuel d’un document XML :
<haïku>古池や蛙飛び込む水の音</haïku>Rendu typique en navigateur :
C’est une belle occasion de mentionner que tous les caractères classés « lettre » en Unicode peuvent être utilisés dans les noms XML. On pourrait ainsi japoniser encore plus le document en utilisant comme identificateur générique de l’élément-document « 俳句 », qui signifie haïku en japonais :
<俳句>古池や蛙飛び込む水の音</俳句>Rendu typique en navigateur :
Cependant, les concepteurs de XML savaient très bien que l’on ne dispose pas toujours d’un équipement de saisie permettant la saisie directe des caractères non latins. Pour cette raison, ils ont inclus dans les règles syntaxiques de XML une convention qui permet de représenter indirectement n’importe quel caractère Unicode (y compris les caractères latins, soit dit en passant). C’est le mécanisme des entités caractère, très analogue à celui des entités prédéfinies.
Un appel d’entité caractère, ou plus simplement, appel de caractère est une courte chaîne de caractères de la forme :
&#nnnnn;
où nnnnn est le numéro (en décimal) d’un caractère Unicode.
Lorsqu’une application XML rencontre un appel de caractère dans le contenu textuel
d’un document XML ou dans une valeur d’attribut, elle remplace cet appel par le
caractère dont le numéro Unicode est nnnnn (le nombre de
chiffres n’est pas nécessairement 5).
Par exemple, l’appel de caractère ℵ
représente le caractère "ℵ" (aleph), parce que le numéro
Unicode de ce caractère est 8501 (en décimal). Ainsi, il est possible
d’inscrire du contenu textuel ou une valeur d’attribut contenant ce
caractère en le représentant par ℵ. Voici un
exemple :
<test test="ℵ">
ℵ
</test>Rendu typique en navigateur :
On peut aussi utiliser le numéro en hexadécimal du caractère, en utilisant la forme suivante d’appel :
&#xnnnnn;
dans laquelle un x suit immédiatement le #. Le
nnnnn est encore interprété comme un
numéro de caractère Unicode, mais cette fois en hexadécimal.
Ainsi, l’appel de caractère ℵ représente
aussi l’aleph (ℵ), parce que 8501 en décimal (le numéro Unicode
de ce caractère) correspond à 2135 en hexadécimal.
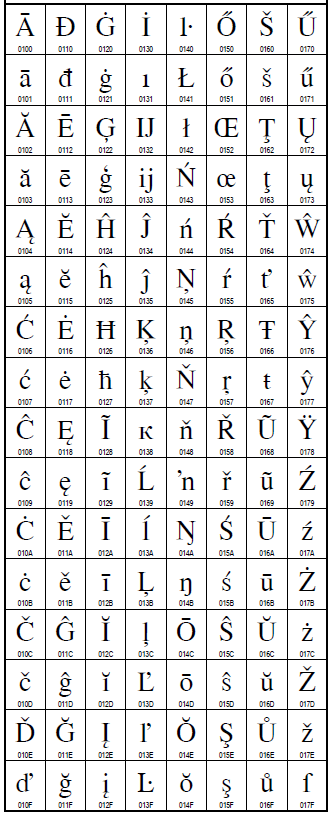
Cette forme d’appel de caractères est particulièrement utile, parce que les numéros de caractères Unicode sont habituellement donnés en hexadécimal. Par exemple, voici une présentation typique d’un (très petit !) extrait du jeu de caractères Unicode. On peut constater que les numéros sont donnés en hexadécimal :
Rien n’empêche d’utiliser un appel de caractère pour
représenter un caractère que l’on peut taper directement au
clavier. Par exemple, le caractère "Ç", que l’on peut
inscrire directement, pourrait aussi être représenté par
Ç parce que le numéro Unicode du "Ç"
est C7 (en hexadécimal). De la même façon, "é"
pourrait être représenté par é et "H" par
H. Il n’y a aucun réel avantage à
utiliser l’appel de caractère dans ces cas, mais ce n’est pas
interdit. On peut même entremêler sans problème les deux
représentations (bien qu’il n’y ait aucun réel
intérêt à le faire); ainsi, les trois documents XML suivants
sont complètement équivalents :
<rire>Hé, hé, hé!</rire>
<rire>Hé, hé, hé!</rire>
<rire>Hé, hé, hé!</rire>
Les trois ont le même rendu en navigateur : 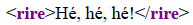
Il faut noter que les entités caractères peuvent être utilisées seulement dans le
contenu textuel d’un élément ou dans une valeur d’attribut. En particulier, un appel de
caractère ne peut pas se retrouver dans un nom XML (par exemple, un nom d’élément ou
d’attribut) pour remplacer une lettre non latine. Ainsi, on ne peut pas inscrire
prénom au lieu de prénom comme nom
d’élément :
MAL FORMÉ :
<prénom>Jeanne</prénom>
Il convient aussi de noter que les entités – tant prédéfinies que caractère – sont inopérantes dans un commentaire. Le commentaire suivant :
<!-- Le numéro Unicode de ℵ est 8501 & c’est bien ainsi. -->
est tout à fait bien formé, mais il n’est pas transformé en :
<!-- Le numéro Unicode de ℵ est 8501 & c’est bien ainsi. -->
lequel, soit dit en passant, est aussi un commentaire tout à fait bien formé.
Voici un bon moment pour synthétiser l’interprétation des documents XML que réalisent les navigateurs Web (en l’absence d’une association avec une feuille de style) :
- / + / ▸ / ▾) apparaissant à gauche de leur balise
de début.& est remplacé
par &).Rappelons enfin que tous les navigateurs vérifient le bien-formé du document XML au moment de son ouverture et refusent d’afficher un document mal formé, produisant plutôt un message d’erreur. Même s’il peut arriver, rappelons-le, qu’une manipulation supplémentaire soit nécessaire pour voir le message d’erreur.