Organisation des fichiers
Nous aborderons l'organisation des fichiers sous deux perspectives : (1) leur organisation physique sur un support de stockage, et (2) leur organisation intellectuelle (c'est-à-dire la manière de définir une arborescence de dossiers).
Organisation physique des fichiers
Pensez à votre journée d'hier et aux données numériques que vous avez créées, modifiées, consultées et essayez d'en faire la cartographie... Courriel (sur votre poste de travail, votre portable, votre téléphone intelligent, votre tablette et/ou sur un serveur de courriel)? Navigation sur Internet? Édition d'un document (en ligne ou sur votre ordinateur)? Vous ferez probablement le constat, (1) que vous avez utilisé de l'information numérique dans votre journée, (2) que cette information numérique venait de sources et d'environnements multiples. Et si vous essayiez maintenant de penser à où, physiquement ces informations résidaient, à comment elles sont organisées, il est possible que vous ne soyez pas nécessairement capable de répondre à cette question. Du fait de la multiplicité des espaces de stockage que l'on utilise, le portrait peut rapidement devenir assez complexe!
L'humain n'a jamais été aussi branché, n'a jamais créé autant d'information, n'a jamais été aussi dispersé sur de multiples plateformes et unités de stockage, et n'a probablement jamais été aussi peu conscient de ce que cela implique concrètement : Où sont nos données? Comment sont-elles organisées? Et ce n'est pas uniquement la faute de l'humain.
L'évolution des technologies fait que la complexité technologique sous-jacente est de plus en plus cachée aux utilisateurs – créant parfois un certain effet de "boîte noire". Par exemple, la structure de fichiers et de dossiers sur une tablette est bien souvent cachée; les fichiers n'existent que par le biais des applications/logiciels. Pourtant, cette information numérique est bien structurée sur le support de stockage. Pour un utilisateur "grand public", il n'est peut-être pas nécessaire de comprendre comment l'information est stockée. Par contre, la professionnelle ou le professionnel de l'information doit le savoir sinon comment gérer cette information numérique?
Nous avons dans la section précédente abordé la notion de format pour observer les fichiers d'un point de vue très micro. Il est maintenant temps de le faire d'une perspective plus macro pour comprendre comment les fichiers sont stockés et organisés physiquement sur un support de stockage.
Arborescence de fichiers et de dossiers
Sur un poste de travail, on peut retrouver de multiples unités de stockage. Selon les systèmes d'exploitation, la manière de les représenter et de les nommer peut varier, mais les principes de base demeurent. Les exemples donnés ci-dessous proviennent de Windows, système d'exploitation très présent dans les organisations.
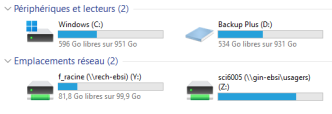
En cliquant sur Ce PC, on pourra voir la liste des unités de stockage « visibles » sur le poste de travail. Sous Windows, chacune est représentée par une lettre. On y retrouvera minimalement le disque dur du poste (ici C:) qui pourrait être partitionné (c'est-à-dire découpé en plusieurs unités). On pourra aussi y voir des périphériques de stockage amovibles comme un lecteur de disquette, une clé USB (ici D:). Finalement, on pourrait y retrouver des emplacements réseau, c'est-à-dire des unités de stockage accessibles via un réseau (ici Y: et Z:).
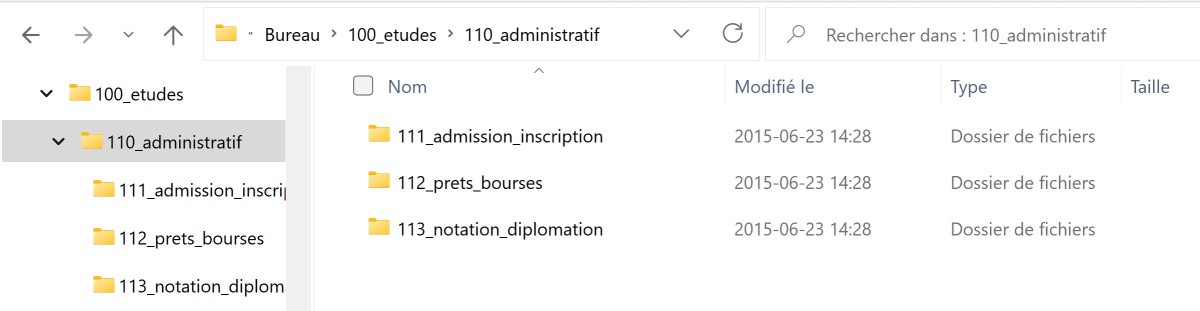
Si on ouvre une unité de stockage, on y retrouvera une arborescence, c'est-à-dire une hiérarchie de dossiers (nommés aussi répertoires), qui sont des contenants, et de fichiers, qui sont des contenus. Les explorateurs de fichiers graphiques des systèmes d'exploitation, comme l'Explorateur de fichiers (Windows), représentent visuellement cette arborescence sous forme de hiérarchie navigable par l'utilisateur. Il est possible d'entrer dans un dossier, pour voir ce qu'il contient, soit d'autres dossiers et/ou des fichiers.
Il est possible aussi de naviguer dans l'arborescence en utilisant le mode commande du système d'exploitation qui est un mode de représentation uniquement textuel.
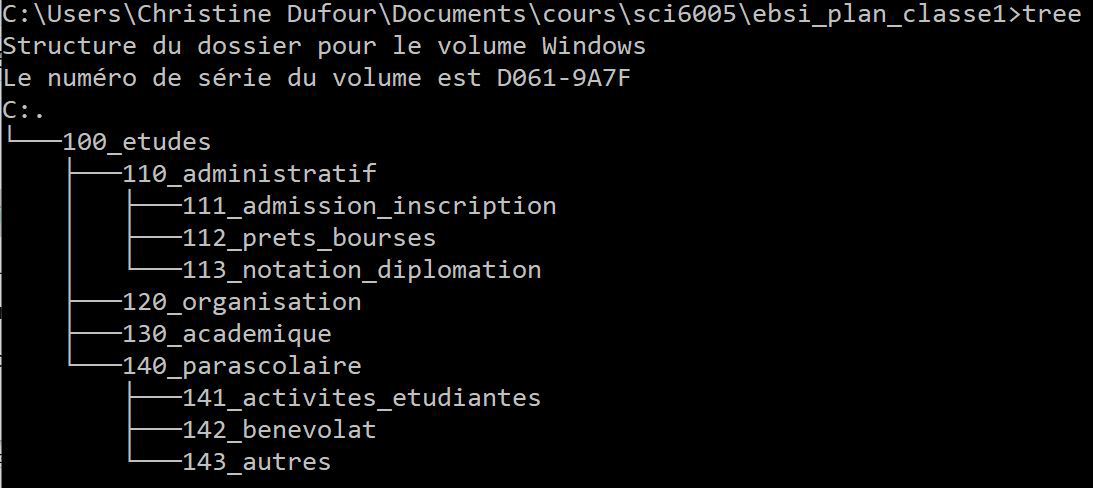
Fut un temps où, pour certains systèmes d'exploitation, seule l'interface textuelle existait. L'interface graphique présentée initialement par Apple a rapidement été adoptée par l'ensemble des systèmes d'exploitation, cette dernière étant plus intuitive pour les « non informaticiens ». L'interface textuelle est maintenant peu connue du grand public, mais elle existe toujours – même Mac OS a son mode commande avec l'application Terminal. Il y a même des tâches que le mode graphique ne peut facilement exécuter rendant fort utile le mode commande (vous en découvrirez une dans le travail pratique sur les principes de base en gestion de l'information numérique).
Chemin absolu ou relatif d'un fichier ou d'un dossier
Nous allons prendre quelques instants pour examiner l'idée de référence à un dossier ou à un fichier. En effet, en sus de savoir où se trouve un fichier dans une arborescence de dossiers, il faut connaître la manière de représenter cette position. Cette référence s'appelle un chemin, chemin qui nous permet d'atteindre un fichier ou un dossier. On retrouve deux types de chemin : chemin absolu et chemin relatif.
Le chemin absolu est le chemin complet donnant la route à suivre à partir de l'unité de stockage jusqu'au fichier ou au dossier que l'on veut atteindre. Le chemin fonctionnera peu importe notre point de départ. C'est un peu comme une adresse physique que l'on donne à quelqu'un. En donnant le numéro civique, le nom de la rue, de la ville, de la province et du pays, peu importe où on se retrouve sur le globe, on pourra vous retrouver.
Par exemple, le chemin absolu du fichier internet.gif dans l'arborescence ci-dessous est C:\site_web\images\internet.gif. Remarquez la syntaxe : on débute par l'unité de stockage pour se rendre jusqu'au fichier en nommant, dans l'ordre, tous les dossiers parcourus pour s'y rendre. Sous Windows, on sépare les différents niveaux par le symbole de barre oblique inversée (\). Sous Mac OS et Linux, c'est le symbole de la barre oblique (/
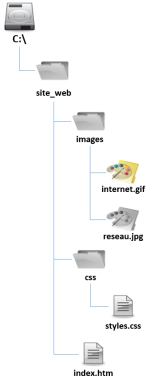
Revenons à l'exemple d'une adresse physique. Si au lieu de l'adresse complète vous dites simplement à votre interlocuteur, par rapport à l'endroit où il se trouve (sa localisation), de marcher deux blocs d'immeubles, de tourner à droite, et de marcher jusqu'à la maison jaune, ce chemin, qui est relatif à sa localisation, ne sera utile qu'à lui, mais il sera beaucoup plus efficace que de lui donner l'adresse complète. On retrouve cette notion de chemin relatif aussi au niveau d'une arborescence de fichiers, la localisation de départ étant le dossier d'où l'on part.
Par exemple, dans l'arborescence ci-dessus, si je me situe dans le dossier site_web et que je veux me rendre jusqu'au fichier internet.gif, le chemin relatif sera simplement de rentrer dans le dossier images et ensuite d'y retrouver le fichier : images\internet.gif. Si je me situe dans le dossier css, il faudrait que je commence par remonter d'un niveau – ce qui est représenté par deux points consécutifs .. – pour ensuite entrer dans le dossier images et y retrouver le fichier internet.gif. : ..\images\internet.gif. Ici aussi, chacun des niveaux est séparé soit par la barre oblique inversée sous Windows, ou par la barre oblique sous Mac OS et Linux.
Vous aurez l'occasion dans le cadre du TP sur les pratiques de base en gestion de l'information numérique de vous pratiquer à composer des chemins absolus et relatifs. Prenez le temps de bien comprendre ces notions qui sont importantes afin de bien intégrer comment concrètement les fichiers et dossiers sont stockés sur un disque dur et comment il est possible de les référencer. Nous verrons un peu plus tard dans la session que ces mêmes notions se retrouvent lorsque l'on développe un site web et que l'on veut y insérer une image par exemple.
Organisation intellectuelle des fichiers
Nous nous sommes attardés dans un premier temps aux considérations techniques de l'organisation des fichiers. Vous vous demandez fort probablement comment procéder pour décider de l'organisation intellectuelle des fichiers, c'est-à-dire de la définition de la hiérarchie des dossiers sur un support de stockage. Comment décide-t-on du nom des dossiers et de leur nombre? Sur votre propre ordinateur, vous avez défini une organisation qui correspond à une logique qui vous est propre et qui vous permet, souhaitons-le!, de facilement organiser et retrouver vos fichiers. Si nous travaillons uniquement en vase clos, sur nos ordinateurs personnels, cette méthode est efficace. Dans un contexte entre autres organisationnel où l'on travaille dans des espaces partagés de stockage de fichiers et où il se peut qu'une autre personne que vous ait à accéder à votre ordinateur (par exemple lors d'une absence), il est souhaitable d'arriver à concevoir une hiérarchie de dossiers qui soit efficace pour tout le monde.
Nous ne nous attarderons que brièvement sur la notion d'organisation intellectuelle des fichiers, cette notion relevant plus d'un cours sur la classification, en particulier en contexte archivistique. Il demeure tout de même important d'y être sensibilisé.e. Nous exploiterons pour ce faire le compte-rendu d'expérience de C. Couture (2009-2010)[1] pour l'élaboration d'un cadre de classification pour la Ville de Brossard.
Pour Couture (2009-2010, p. 73) "[l]a première étape, à notre avis, de tout projet de gestion de documents numériques [doit] en être une d'organisation de l'information". L'auteure fait ainsi ressortir toute l'importance, dans un contexte organisationnel, que revêt la définition d'un plan (cadre) de classification commun en raison, entre autres, des mouvements de personnel et des manières différentes que les personnes peuvent avoir d'organiser les documents. Les informations sont éparpillées, parfois sur des ordinateurs personnels, d'autres fois dans des espaces partagés. Cet éparpillement et ce foisonnement dans les manières d'organiser les fichiers causent des problèmes de repérage qui peuvent être minimisés par l'adoption d'un cadre de classification commun (p. 73).
L'auteure identifie trois principales contraintes à l'élaboration d'un plan de classification pour les documents numériques qui rejoignent certaines des préoccupations techniques abordées précédemment (p. 74-75) :
Nombre de niveaux de la structure de classification : le chemin absolu d'un fichier ne pouvant dépasser 260 caractères, il est conseillé de limiter au minimum le nombre de niveaux. L'auteure suggère de ne pas dépasser quatre niveaux. De plus, l'auteure souligne le côté expérience-utilisateur : "pour qu'il [cadre de classification] soit bien accepté pour les documents numériques, le cadre de classification doit imposer le moins de « clics » possible, donc le moins de niveaux possible" (p. 74), un autre argument en faveur d'une arborescence qui ne comporte qu'un nombre restreint de niveaux.
Taille des noms de fichiers : Toujours en raison du nombre de caractères maximal du chemin absolu d'un fichier, il est important que chacun des termes qui composent le nom d'un fichier soit court et significatif. Nous ajouterons à ce conseil fort judicieux un argument complémentaire : la signification d'un fichier repose sur son nom, mais aussi sur le nom des dossiers qui le contiennent. La hiérarchie apporte un contexte qu'il n'est pas nécessaire de dédoubler dans le nom du fichier comme tel. Par exemple, si vous conservez les procès-verbaux de votre unité dans un dossier nommé "proces_verbaux", il est inutile d'inclure le terme "proces_verbaux" dans les fichiers eux-mêmes à moins que ces fichiers se retrouvent parfois "hors contexte".
Règles de nommage des fichiers : Finalement, Couture souligne la pertinence d'imposer des règles quant à la manière de nommer les fichiers et les dossiers, pour normaliser la présentation des informations, ce qui en facilite la lecture, mais aussi pour éviter des problèmes techniques. Les règles adoptées pour la Ville de Brossard sont présentées en annexe à titre d'exemples.
Pour l'élaboration du cadre de classification, les applications antérieures utilisées à la Ville de Brossard ont permis de recueillir des informations quant aux activités de la ville - le cadre se basant sur ces activités - et aux types de documents produits. Il est en effet important de bien connaître le milieu pour lequel un cadre de classification est développé pour qu'il y soit bien adapté. De plus, plusieurs références ont été exploitées pour entre autres identifier des bonnes pratiques, dont des plans de classification d'autres villes, la norme ISO-15489 - Records management, et une thèse de doctorat sur la classification ( Mas, 2007[2]) .
Pour préciser le vocabulaire utilisé pour nommer les dossiers, les documents de la ville ont été consultés ainsi que les employés. La consultation des employés remet à nouveau de l'avant l'importance de bien adapter un cadre de classification au milieu pour lequel il est développé. Cela en facilitera l'adoption en sus de le rendre plus efficace.
La structure du cadre défini comporte, d'une part, une structure corporative qui peut être utilisée par toutes les unités de la Ville de Brossard, et, d'autre part, des classes personnalisées pour les unités. On y retrouve donc à la fois une structure commune dans un but d'uniformisation ainsi que de la flexibilité pour prendre en compte les particularités des unités.