Création d'une base de données dans phpMyAdmin
La création d'une base de données dans phpMyAdmin implique différentes étapes décrites ci-dessous : il faut y définir, dans cet ordre, les tables, leurs champs, les index associés et finalement les relations entre les tables.
Remarque :
Le Guide abrégé d'utilisation de phpMyAdmin 5.2.3 est un complément à la matière ici présentée.
Création d'une table de données
La création d'une table de données se fait dans phpMyAdmin en cliquant premièrement sur la base de données où l'on veut ajouter la table et, dans l'onglet Structure, en indiquant le nom de la table à ajouter ainsi que le nombre de champs (colonnes) de cette dernière dans la zone Créer une nouvelle table au bas de l'écran.
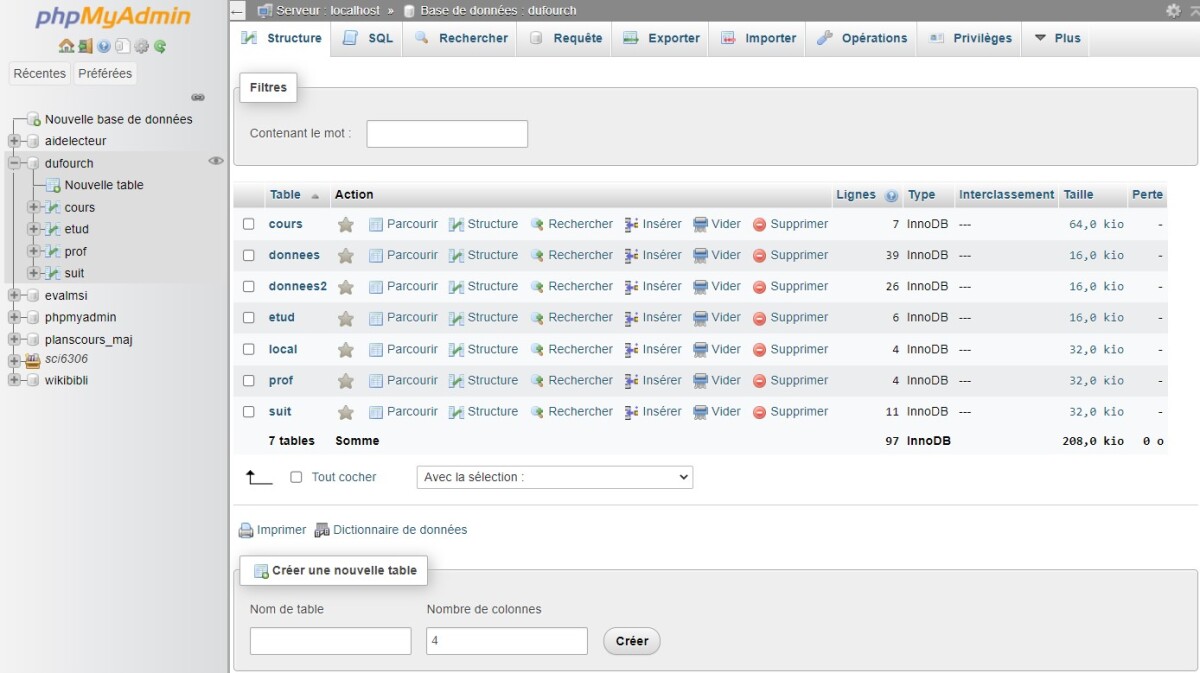
Lorsque l'on clique par la suite sur Créer, on se retrouve à l'interface nous permettant de définir les caractéristiques de la table ainsi que de ses champs.
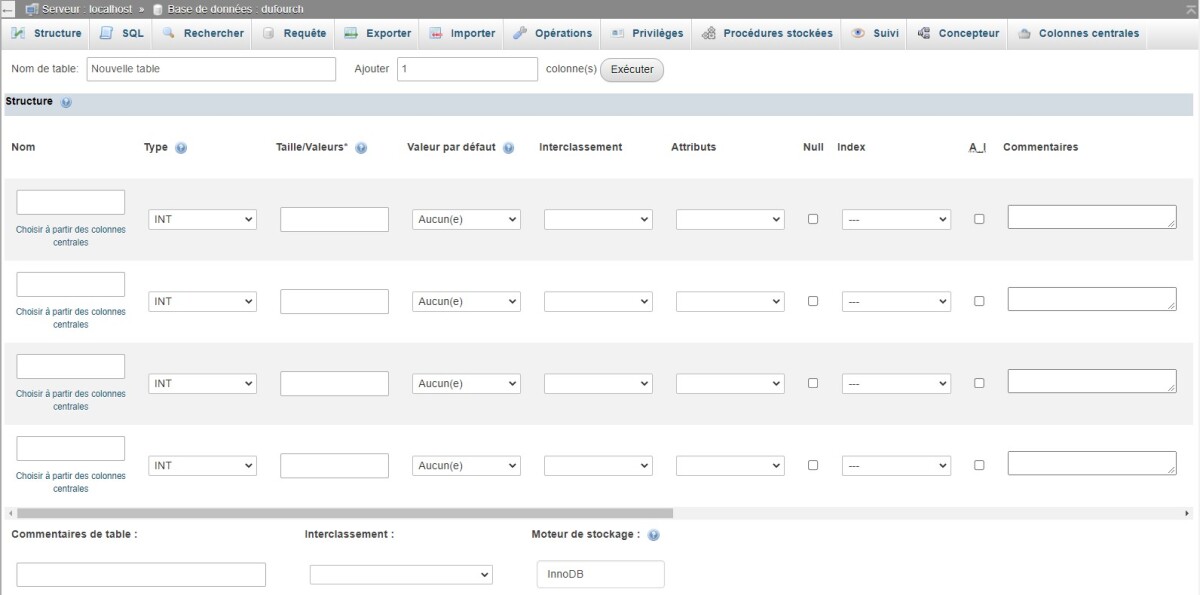
Les principaux éléments génériques à définir sont les suivants :
Nom de la table : nom assez court et représentatif du contenu de la table
Commentaires sur la table : description succincte du contenu de la table (complément au nom)
Interclassement : jeu de caractères et caractéristiques du classement
Par exemple, utf8_general_ci = Unicode (multilingue), insensible à la casse
Note : à définir si on ne veut pas retenir l'interclassement défini au niveau de la base de données (ce qui est relativement rare)
Moteur de stockage
Selon les besoins sur le plan de la performance et de la protection de l'intégrité des données (entre autres)
Le plus fréquemment utilisé : InnoDB (celui utilisé par défaut lorsque l'on crée une table)
Définition des propriétés des champs
Après avoir défini les caractéristiques génériques de la table, il faut définir les propriétés de ses différents champs en remplissant les paramètres pertinents. Les principales propriétés à définir sont les suivantes :
Nom du champ (conseil : rester simple!)
Type de données (voir dans la documentation complémentaire la section Principaux types de champ sous MySQL)
Taille du champ ou valeurs prédéfinies (selon le type de données)
Valeur par défaut (s'il y a lieu)
Interclassement (s'il diffère de celui de la table)
Attributs particuliers (en particulier « unsigned » pour les champs numériques qui n'acceptent que les valeurs positives)
Acceptation ou non de la valeur nulle (acceptation = champ facultatif)
Champ dont la valeur s'incrémente automatiquement (A_I)
Commentaires (pour rappeler, par exemple, les principales règles d'écriture)
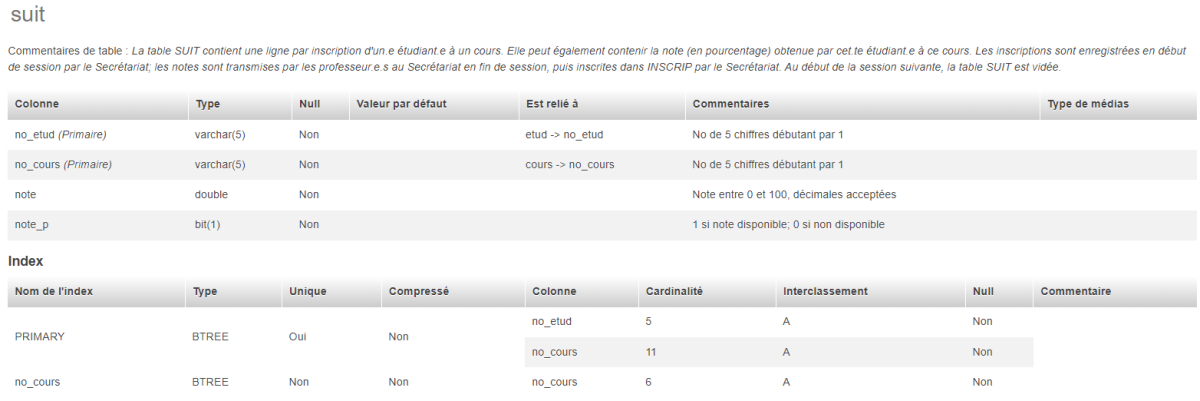
Exemple : Propriétés du champ DESCR dans la table COURS de la base de données INSCRIP
Le champ DESCR de la table COURS de la base de données INSCRIP, dans le schéma relationnel de la BD, a pour caractéristiques d'être de type Caractère, d'une taille de 300 et d'être obligatoire. Voici comment ces caractéristiques se traduisent dans phpMyAdmin :

À noter :
La longueur d'une description étant variable, le type VARCHAR a été privilégié pour éviter d'enregistrer inutilement des espaces vides afin d'arriver à la taille maximale de 300.
La taille a été définie à 300.
Comme il n'y a pas de "valeur type" possible pour une description, aucune valeur par défaut n'est précisée. Un exemple où une valeur par défaut pourrait être pertinente est le cas d'un champ PAYS dans une base de données où l'on sait que la majorité des enregistrements auront pour valeur CANADA. Afin d'accélérer la saisie, on peut définir CANADA comme valeur par défaut qui sera ainsi inscrite automatiquement lors de la création d'un nouvel enregistrement et modifiable, bien entendu, au besoin par la suite.
Comme les données du champ DESCR seront dans la même langue que l'ensemble de la base de données, l'interclassement par défaut - c'est-à-dire celui de la table de données qui est en fait celui de la base de données au complet - a été conservé.
Aucun attribut particulier n'est nécessaire.
La case pour Null n'a pas été cochée. Le champ étant obligatoire, on ne veut en effet pas permettre la saisie de la valeur NULL.
Le contenu de ce champ ne consistant pas à un chiffre auto-incrémenté, la colonne A_I n'a pas été cochée.
Finalement, une courte description de la nature du champ a été ajoutée dans les commentaires associés à ce dernier.
Définition des index
En sus de définir, pour une table, les propriétés de ses champs, il faut définir le ou les index qui seront utiles et nécessaires au bon fonctionnement de la base de données. Les index servent à différents plans :
Bien que l'indexation d'un champ ne soit pas nécessaire pour qu'il soit cherchable (sauf pour la recherche plein texte), elle permet d'accélérer la recherche. Il faut donc prendre soin d'indexer les champs où l'on prévoit des recherches fréquentes.
Les index sont obligatoires dans certains contextes :
Pour les clés primaires (pour contrôler l'unicité de leurs valeurs dans une table),
Pour les champs servant de clés externes (pour s'assurer qu'un enregistrement dans une table liée a bien une correspondance dans la table principale),
Pour les champs à valeurs uniques (pour contrôler l'unicité de leurs valeurs),
Pour les champs où l'on souhaite faire de la recherche plein texte.
On retrouve quatre principaux types d'index :
Primary : pour une clé primaire,
Unique : pour avoir des valeurs uniques dans un champ autre que la clé primaire,
Fulltext : pour la recherche plein texte,
Index : index-mots sans caractéristique particulière (entre autres pour les clés externes).
Un index peut se faire sur un seul champ comme il peut en regrouper plusieurs. C'est le cas, par exemple, d'une clé primaire multichamp qui regroupera dans un index tous les champs qui la composent.
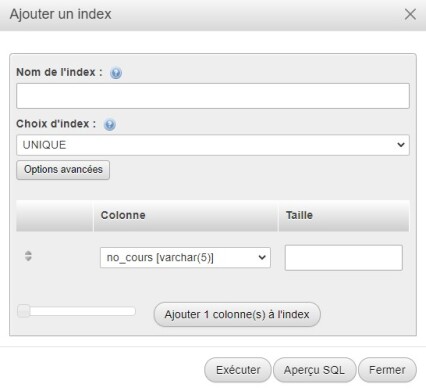
L'interface pour la définition des index est accessible à partir de l'onglet Structure d'une table, sous la table présentant ses différents champs. Lorsque l'on clique sur Exécuter à droite de "Créer un index sur...", l'interface proposée nous permet de nommer l'index à ajouter, d'en choisir le type, de préciser le ou les champs (colonnes) qui le constituent :
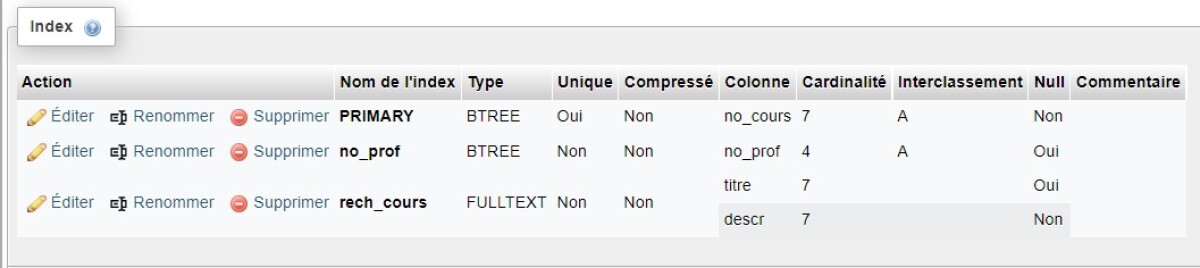
Exemple : Index définis pour la table COURS de la base de données INSCRIP
La table COURS de la base de données INSCRIP possède trois index :
À noter :
Le premier index nommé PRIMARY est celui de la clé primaire de la table. Comme cette clé primaire est composée d'un seul champ (NO_COURS), il n'y a qu'un seul champ précisé pour cet index. Puisqu'il s'agit d'une clé primaire, l'unicité des valeurs est contrôlée. Dans cet affichage, seul le type générique d'index est indiqué, soit ici BTREE. Pour voir le type spécifique, il suffit de cliquer sur Éditer. Cet index est de type Primary. Il est créé automatiquement lorsque l'on définit la clé primaire d'une table. La création d'une clé primaire dans une table se fait dans l'onglet STRUCTURE, en cochant le ou les champs qui serviront de clé primaire et en cliquant sur Primaire qui se trouve sous la table des champs.
Le deuxième index nommé no_prof correspond à un index pour une clé externe. Le champ NO_PROF sert en effet pour relier un cours à la table PROF afin d'obtenir les informations sur le professeur ou la professeure associée à ce cours. Comme un.e professeur.e peut enseigner plusieurs cours, l'unicité des valeurs n'est pas recherchée. Cet index est de type Index. Il faut créer les index sur les champs de clé externe avant de définir les relations entre les tables. La création de ce type d'index peut se faire dans l'onglet STRUCTURE, en cochant le champ à indexer et en cliquant sur Index qui se trouve sous la table des champs.
Le troisième index nommé rech_cours a été défini pour permettre les recherches plein texte sur les champs à contenu textuel plus dense pour lesquels on pressentait l'utilité de ce type de recherche. Pressentant des recherches par thématique, il a été décidé de joindre les deux champs TITRE et DESCR dans un seul index de type Fulltext. Cet index peut aussi se créer à partir de l'onglet STRUCTURE, en cochant le ou les champs à indexer et en cliquant sur Texte entier qui se trouve sous la table des champs.
Comme des recherches fréquentes ne sont pressenties que pour les champs TITRE et DESCR, qui sont déjà indexés, aucun autre index n'a été ajouté à cette table.
Définition des relations entre les tables
Maintenant que l'ensemble des éléments constitutifs des tables est défini, il est possible de procéder à la définition des relations entre les tables. Bien qu'une base de données puisse en théorie être fonctionnelle sans définir les relations explicitement, dans la pratique, l'absence de relations provoquera des problèmes sérieux sur le plan de la cohérence des données. Ce sont les relations qui permettent de maintenir cette cohérence en permettant la mise à jour des données liées entre deux tables. Par exemple, dans INSCRIP, c'est la présence d'une relation entre les tables ETUD et SUIT qui permet d'automatiquement effacer les inscriptions à un cours si l'on supprime un.e étudiant.e de la table ETUD, ou de modifier le numéro d'étudiant.e dans la table SUIT suite à une modification du numéro dans la table ETUD. Différents types "d'interaction" sont possibles entre deux tables liées. Il y a deux contextes où il faut préciser le type d'interaction pour une relation entre deux tables : (1) ce qu'il faut faire si on met à jour le(s) champ(s) liant les deux tables (on update), et (2) ce qu'il faut faire si on efface un enregistrement dans une table liée (on delete).
Trois types d'interaction sont possibles :
CASCADE : les actions sur la table principale se répercutent sur la table liée
Par exemple, dans INSCRIP, si on supprime un cours, toutes ses inscriptions sont effacées dans SUIT.
Permet de préserver l'intégrité référentielle des données en s'assurant que chacune des valeurs de la clé externe de la table liée correspond à un enregistrement de la table principale.
SET NULL : si on supprime un enregistrement de la table principale, les enregistrements correspondant dans la table liée ne sont pas effacés, mais la valeur de la clé externe est changée pour NULL
Par exemple, dans INSCRIP, on peut se demander si c'est une bonne idée lorsque l'on efface un.e professeur.e de voir tous ses cours être effacés en cascade... Peut-être serait-il préférable de plutôt mettre la valeur NULL dans le champ NO_PROF de la table COURS. Une condition nécessaire pour cette action est bien entendu que le champ accepte les valeurs NULL (donc soit facultatif), ce qui est bien le cas pour NO_PROF dans la table COURS.
RESTRICT : on ne peut pas modifier la clé primaire ou effacer un enregistrement de la table principale s'il existe un enregistrement correspondant dans la table liée
La définition des relations peut se faire soit en mode plus graphique en utilisant le Concepteur, ou en mode plutôt textuel à partir de l'onglet Structure d'une table en cliquant sur Vue relationnelle. Un des avantages d'utiliser la vue relationnelle de la table où se trouve la clé externe est qu'il est possible d'y définir des contraintes de clé externe portant sur plusieurs champs simultanément (ce qui est le cas lorsque la clé primaire de la table liée est une clé multichamp). De plus, la vue relationnelle indique explicitement le type d'interaction définie pour la mise à jour et la suppression d'enregistrement.
Attention :
Il est bien important d'attendre d'avoir bien tout défini au niveau des tables, en particulier de s'assurer que les champs servant de clés externes ont bien été définis exactement du même type de données dans les deux tables liées, ainsi que les index bien définis pour ces clés externes. Procéder un peu trop par essai-erreur lors de la définition des relations dans une base de données peut entraîner une certaine instabilité de la base de données, voire même la corrompre.
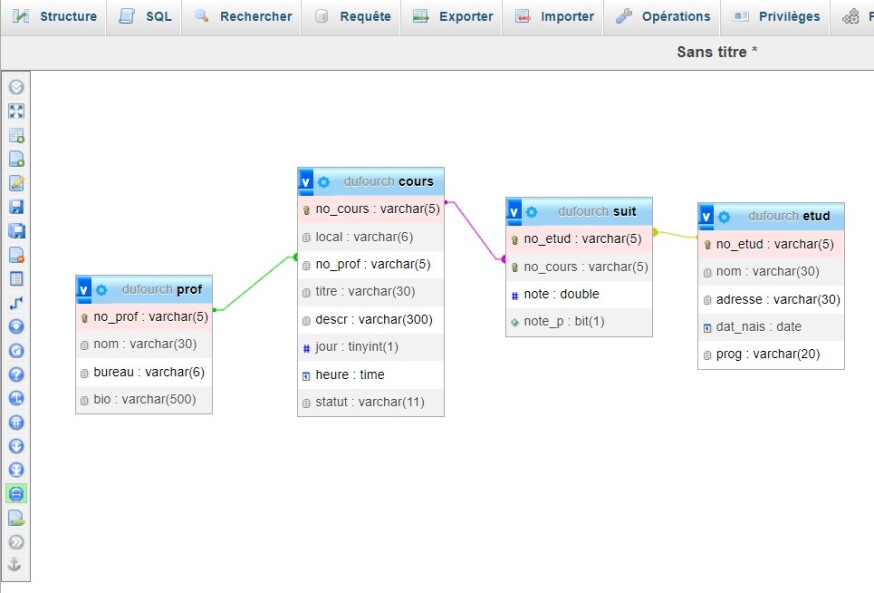
Exemple : Relations définies pour la table SUIT de la base de données INSCRIP
La table SUIT de la base de données INSCRIP est liée à deux tables, soit la table COURS et la table ETUD :
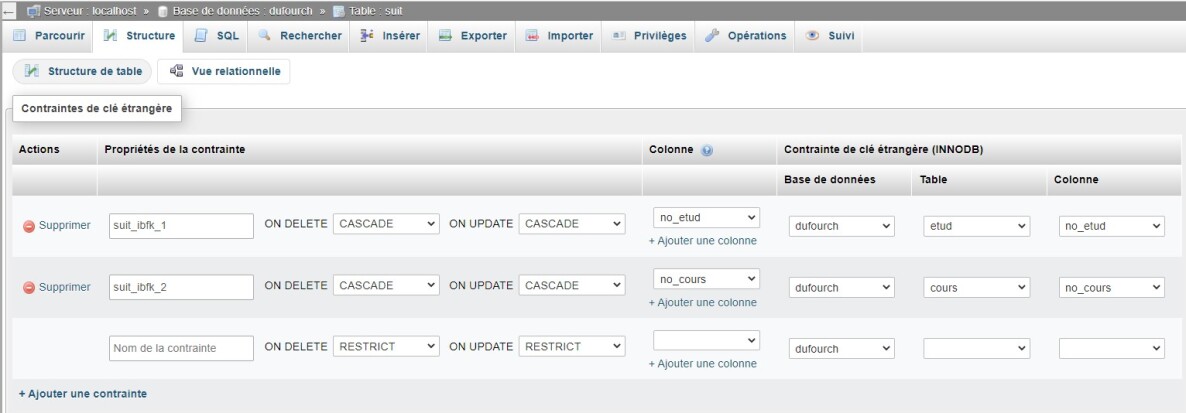
Si on regarde plus précisément les types de relation définis, on remarque que tant pour la modification que pour la suppression, l'action retenue est de répercuter (cascade) sur SUIT les actions faites sur les tables COURS et ETUD. Ainsi, si on supprime l'enregistrement pour un.e étudiant.e, toutes les inscriptions de cet.te étudiant.e disparaissent de la table SUIT. De même, si on change le numéro d'un cours, ce dernier sera modifié dans la table SUIT.
Génération du dictionnaire de données
Il est possible de générer, à partir de l'onglet Structure d'une base de données, un "dictionnaire de données" où on retrouve, pour chaque table, le détail sur ses champs et ses index. Cette synthèse des caractéristiques des tables, de leurs champs et de leurs index peut se révéler fort utile lorsque vient le temps de vérifier que la structure définie correspond bien au schéma relationnel de la BD.