Modélisation sémantique
La modélisation d'une base de données relationnelles comporte les trois étapes habituelles pour toute modélisation :
La conceptualisation de la réalité à représenter
La représentation de cette conceptualisation
La validation de la modélisation proposée
Les deux premières étapes (conceptualisation et représentation) peuvent être effectuées conjointement lors de la modélisation sémantique de la base de données. La validation peut passer quand à elle par un retour vers la ou les personnes à la source du besoin pour une base de données ainsi que par l'exercice de produire des exemples de contenu pour chacune des tables prévues dans votre modélisation.
La modélisation sémantique d'une base de données relationnelle permet d'ajouter à la compréhension d'une base de données et d'ainsi pouvoir répondre plus intelligemment aux interactions de l'utilisateur ou de l'utilisatrice. Cette modélisation est utile au processus de conception systématique des bases de données. Elle se fait habituellement en dehors du SGBD.
L'objectif de cette modélisation est de représenter une certaine réalité selon le modèle relationnel pour pouvoir construire, par la suite, une base de données relationnelle. Plusieurs approches peuvent être utilisées pour modéliser une BD, dont l'approche entités-relations (E-R) qui est parmi les plus connues et utilisées.
Approche entités-relations (E-R)
Cette approche est fondée sur le modèle E-R (entités-relations) défini par Chen (1976) et raffiné par la suite. On y retrouve représentés plusieurs objets sémantiques :
Entités : objets que l'on peut et veut distinguer (par exemple, des étudiant.e.s, des cours, etc.).
Relations : connections entre des entités (par exemple, des inscriptions qui relient les étudiant.e.s aux cours). Une relation possède une cardinalité qui représente la manière dont les enregistrements des deux tables connectées sont liés.
Attributs : propriétés décrivant une entité ou une relation (par exemple, le nom d'un.e étudiant.e qui décrit l'étudiant.e, la note obtenue à un cours qui caractérise l'inscription d'un.e étudiant.e à un cours) que l'on veut documenter dans la BD. Certains attributs permettent d'identifier de manière unique les enregistrements dans une table comme, p. ex., NO_COURS dans la table COURS. On parle en ce cas d'une clé primaire[1].
Un des résultats de la modélisation entités-relations est un diagramme Entités-Relations qui encapsule visuellement les différents objets sémantiques identifiés. Classiquement, les entités sont représentées par des rectangles, les relations par des losanges et les attributs par des ovales. Le diagramme Entités-Relations qui suit représente la BD INSCRIP que nous utiliserons comme exemple tout au long de la session. Il s'agit d'une BD pour gérer les cours, les professeur.e.s ainsi que les étudiant.e.s pour un établissement d'enseignement (voir Documentation complémentaire - Dictionnaire de données d'INSCRIP pour la description détaillée de cette base de données).
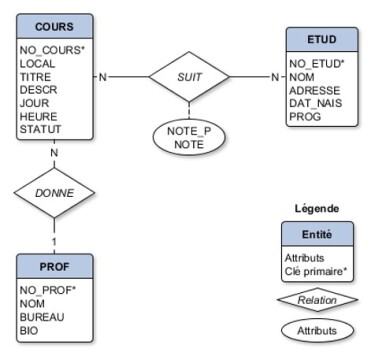
On retrouve dans cette base de données 3 entités, soit les cours, les professeur.e.s et les étudiant.e.s. Deux relations connectent ces entités, soit une relation entre les cours et les étudiant.e.s qui représente l'inscription d'un.e étudiant.e à un cours, et une relation entre les cours et les professeur.e.s pour représenter le lien d'enseignement. Ces deux relations illustrent les deux principaux types de cardinalité que l'on retrouve dans une base de données relationnelle :
Relation 1-N : La relation DONNE est une relation 1-N parce que, dans le contexte représenté, un.e professeur.e peut être associé.e à plusieurs cours (d'où le N du côté de l'entité COURS), tandis qu'un cours n'est associé qu'à un.e seul.e professeur.e comme il n'y a pas de cours donné simultanément par plus d'un.e professeur.e (d'où le 1 du côté de l'entité PROF).
Relation N-N : On retrouve une relation N-N dans INSCRIP, soit la relation SUIT. En effet, un.e étudiant.e peut suivre plusieurs cours - d'où le N du côté de l'entité SUIT, et un cours peut être suivi par plusieurs étudiant.e.s - d'où le N du côté de l'entité ETUD.
L'identification de la cardinalité des relations est importante, comme la cardinalité aura un impact direct sur la manière dont la conceptualisation sémantique sera convertie en structure de tables et de champs. Cet impact sera illustré dans une section subséquente.
Selon le contexte, il arrive que l'on puisse hésiter pour un certain élément entre le définir comme une entité ou comme un attribut. Par exemple, dans INSCRIP, on retrouve un attribut LOCAL comme caractéristique de l'entité COURS. Pourquoi ne pas en avoir fait une entité à part entière ? Il y a deux questions à se poser :
Est-ce qu'on s'intéresse directement aux locaux comme tels ou bien indirectement comme une caractéristique des cours?
Et si aucun cours ne se donne dans un local, veut-on conserver dans la base de données des informations sur ce local?
La réponse peut varier en fonction de l'objectif de la BD :
Si la base de données sert à gérer des cours, alors le local nous intéresse comme caractéristique d'un cours uniquement; il s'agit donc d'un attribut.
Si la base de données sert à gérer l'attribution des locaux, alors le local nous intéresse même si aucun cours ne s'y donne. On voudrait ainsi pouvoir conserver des informations autres que le numéro du local, p. ex. le nombre de places ou le type d'équipements. Il s'agit en ce cas d'une entité.
Pour plus d'information sur la distinction entité et attribut, voir Comment distinguer une entité d'un attribut / Marcoux[2].
Comme la modélisation sémantique d'une BD relationnelle se fait souvent à l'extérieur du SGBD, il est légitime de se demander avec quoi dessiner le diagramme entités-relations. Deux éléments sont à retenir pour faire un choix :
Il faut choisir une application capable de facilement faire des formes, du texte et des lignes. Il faut pouvoir respecter la symbolique prédéfinie. Ce peut être un logiciel de traitement de texte (Word, Writer), de présentique (PowerPoint, Keynote), de diagramme et synoptique (yEd, Visio), de dessin (FireWork), etc.
Il faut aussi prendre en compte vos préférences. Utilisez un outil accessible et que vous connaissez bien. Il faut aussi vous rappeler qu'il ne s'agit pas d'une œuvre d'art. Si vous voulez en explorer un, yEd de la compagnie yWorks (gratuit, Windows/Linux/Mac) est installé sur les postes au laboratoire et fait bien le travail (les diagrammes E-R dans le matériel de cours ont été produits avec yEd). Vous retrouverez sur le site du cours un mode d'emploi abrégé pour cet outil.
Exercice : Modélisation d'un groupe de recherche
Soit le contexte d'un groupe de recherche universitaire ayant les caractéristiques suivantes :
Le groupe représente une communauté de chercheur.se.s (professeur.e.s, post-doctorant.e.s, étudiant.e.s, etc.) se regroupant autour d'une thématique afin de produire de nouvelles connaissances par le biais de différents projets de recherche.
Le groupe est associé à des projets de recherche, financés ou non, regroupent en tout ou en partie les membres du groupe de recherche.
Certains projets peuvent être le sujet du mémoire ou de la thèse d'un.e des étudiant.e.s membre du groupe de recherche qui est encadré en ce cas par un.e des professeur.e.s du groupe de recherche.
Parmi les « livrables » du groupe de recherche on retrouve la diffusion des résultats (articles, etc.).
Exercice : Identifiez, en groupe de 2-3 personnes, les différents éléments permettant de représenter ce contexte (entités, relations, principaux attributs). Nous ferons un retour ensemble par la suite.
Conversion d'un diagramme E-R en tables
Le diagramme E-R représente la modélisation sémantique d'un contexte et non directement sa structure en tables (bien qu'il n'en soit pas si loin que ça!). L'étape suivant l'élaboration du diagramme E-R est ainsi de le convertir en structure de tables et de champs afin de pouvoir ensuite l'implanter dans un SGBD. On peut découper le processus de conversion d'un diagramme E-R en tables en 6 grandes étapes :
Étapes | Précisions |
|---|---|
1. Transformation des entités en tables de données |
|
2. Traitement des relations |
|
3. Réévaluation des clés primaires en fonction de l'ensemble des champs créés |
|
4. Définition des types pour chaque champ |
|
5. Détermination des champs à valeur NULL (champs facultatifs) ou permettant la chaîne vide | |
6. Règles d'écriture particulières (peuvent être générées par exemple via un masque) |
|
Exemple : Exemple de conversion pour la base de données INSCRIP
Soit le diagramme E-R de la base de données INSCRIP
La première étape consiste à transformer les entités en tables et les attributs en champs. Par exemple, l'entité COURS devient la table COURS et ses différents attributs (p. ex. LOCAL) deviennent des champs pour cette table :
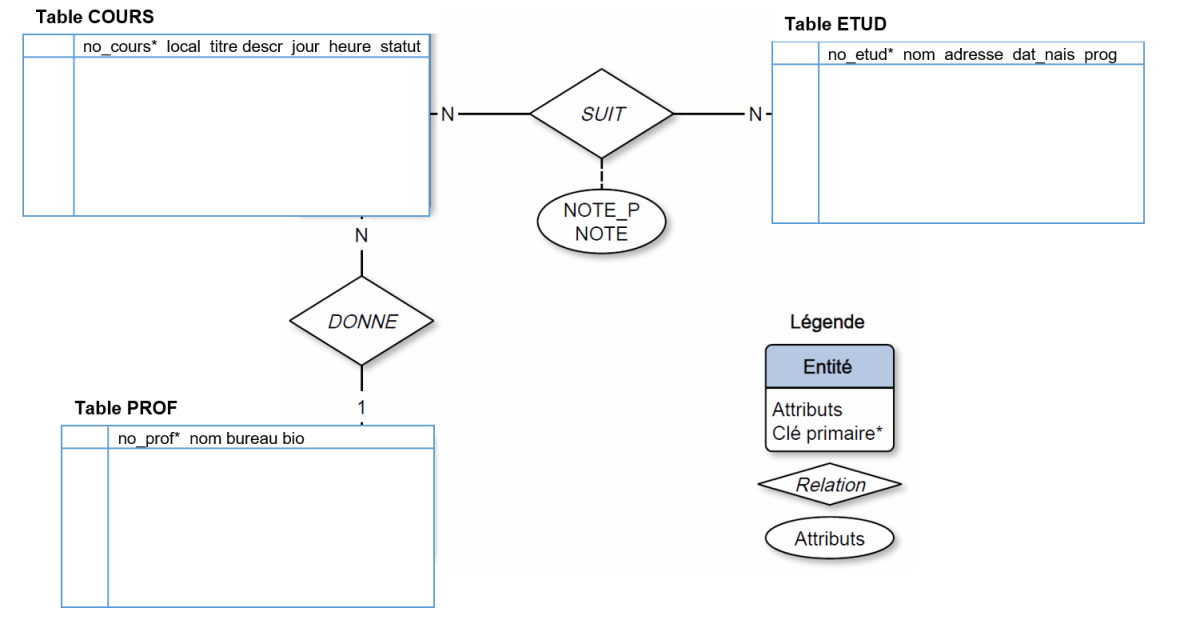
La deuxième étape vise à transformer les relations 1-N en clés externes. La seule relation 1-N dans le diagramme E-R d'INSCRIP est la relation DONNE liant les entités COURS et PROF. La transformation ajoutera dans la table du côté N (soit COURS), le ou les champs servant de clé primaire à la table du côté 1 (soit PROF). On ajoute ainsi le champ NO_PROF dans la table COURS :
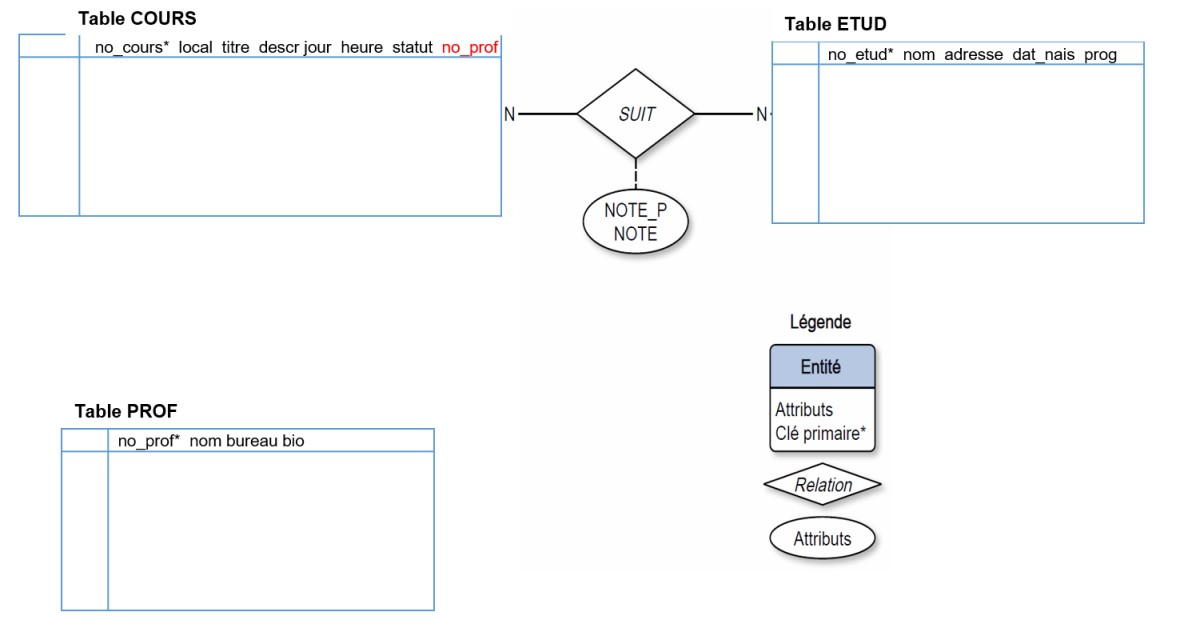
La deuxième étape traitera aussi les relations N-N qui seront transformées en tables. Pour INSCRIP, la seule relation N-N est la relation SUIT. Cette dernière deviendra la table SUIT et sa clé primaire sera la combinaison des clés primaires des deux tables qu'elle relie, soit le champ NO_COURS pour la table COURS et le champ NO_ETUD pour la table ETUD :
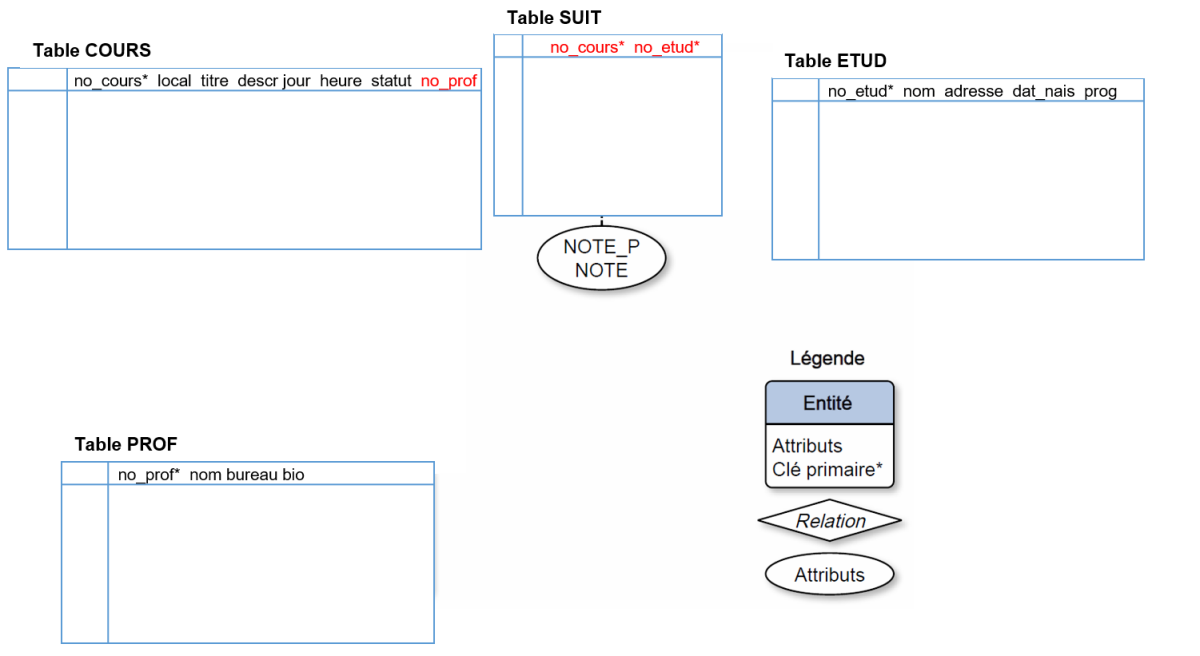
Pour terminer la deuxième étape, il faut transformer les attributs des relations N-N en champs dans la table créée pour cette relation. Dans INSCRIP, la relation SUIT comporte deux attributs, soit NOTE et NOTE_P. Ces deux attributs deviendront ainsi des champs dans la table SUIT :
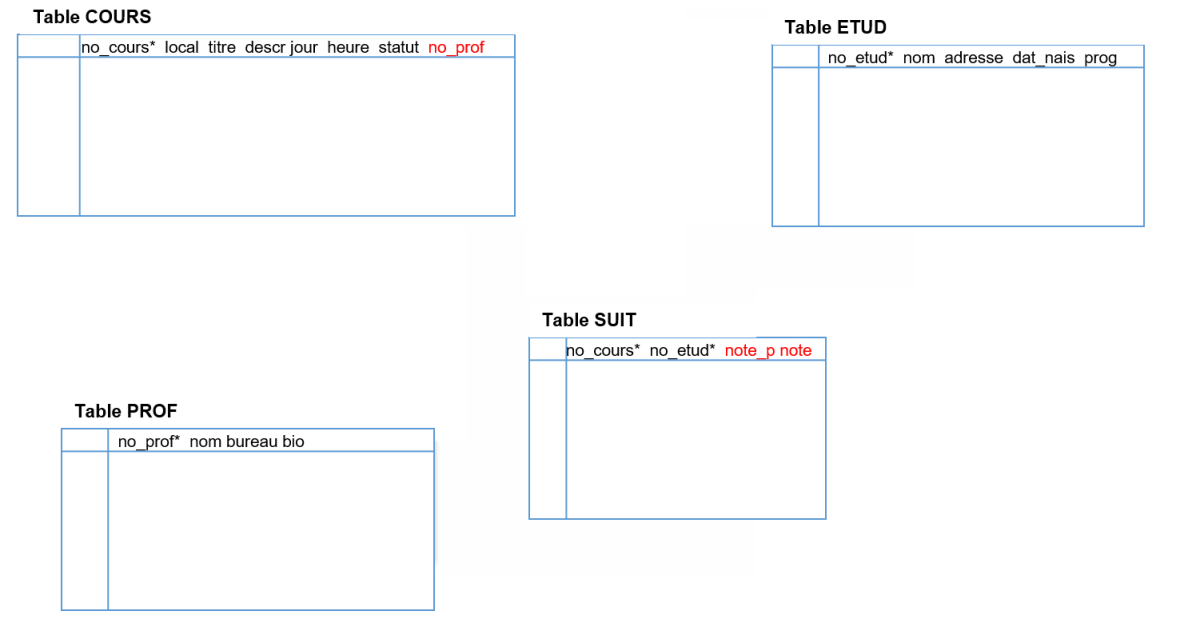
Maintenant que l'ensemble des tables ont été créées, il faut prendre le temps à la troisième étape de réévaluer les champs identifiés lors de la conception du diagramme E-R comme clés primaires. Sont-ils toujours pertinents ou y a-t-il d'autres champs qui pourraient agir comme clé primaire de manière plus efficace? Pour INSCRIP, les choix initiaux faits sont les plus pertinents. Il n'est donc pas nécessaire de changer.
C'est à la quatrième étape qu'il est temps de s'interroger quant aux meilleurs types de données pour les différents champs que l'on retrouve dans les tables. Les quatre principaux types sont (1) caractères (= information textuelle), (2) numérique (= chiffres), date/heure (= date et/ou heure), logique (=Oui ou Non / Vrai ou Faux). P. ex., quel type de données s'attend-on à retrouver pour le titre d'un cours? Un champ de type caractère semble un choix assez évident! Mais de quelle longueur? Il faut en effet prendre soin, entre autres pour les champs de type caractère, d'en identifier la longueur maximale.
Le cœur de la cinquième étape est l'identification des champs qui acceptent la valeur NULL, c'est-à-dire qui sont des champs facultatifs. Par exemple, devrait-on toujours avoir les informations nécessaires pour remplir le champ BIO pour un.e professeur.e? La décision, dans certains cas, est facile lorsque l'information pour un champ n'existe pas toujours. Imaginons, par exemple, que nous ayons prévu un champ pour le numéro de cellulaire dans la table ETUD. Bien que cela soit plus rare, il se peut qu'un.e étudiant.e n'ait pas de téléphone cellulaire. Le champ doit en ce cas être facultatif. Dans d'autres cas, la décision peut être moins directe car demandant une réflexion sur la charge de travail impliquée par la saisie de certains champs. Par exemple, le champ BIO pour un.e professeur.e est un champ qui peut demander un certain travail de création et de saisie de l'information. Même si, dans l'idéal, on pourrait souhaiter qu'il soit toujours rempli, il peut être plus raisonnable de le laisser facultatif.
Finalement, en dernière étape vient la précision des règles d'écriture pour chacun des champs avec l'identification, s'il y a lieu, de moyens de s'assurer de respecter ces règles d'écriture (p. ex. par des masques de saisie). Certains champs seront à saisie relativement libre, comme la biographie des professeur.e.s. D'autres auront une forme bien précise comme le numéro identifiant un cours.
Pour des explications complémentaires sur la conversion d'un diagramme entités-relations en structure de tables relationnelles, voir le texte Conversion d'un diagramme E/R en structure de tables relationnelles / Marcoux[5].
Schéma relationnel
Le résultat de la conversion d'un diagramme E-R en structure de tables permet de développer un élément de documentation fort important pour une BD relationnelle, soit son schéma relationnel. Il s'agit de son dictionnaire de données dans lequel sera précisé les éléments suivants :
Contexte général de la base de données
Structure générale de la base de données, incluant son diagramme entités-relations
Structure des tables, incluant la description des champs (à quoi ils correspondent, quel est leur format, les valeurs possibles, etc.)
Contraintes additionnelles sur les contenus s'il y a lieu (c'est-à-dire des restrictions sur certains contenus qui ne peuvent se définir par les caractéristiques d'un champ (par exemple des restrictions d'un champ par rapport à la valeur d'un autre champ))
Exemples de contenus valides (pour illustrer les règles de saisie)
Vous retrouverez à titre d'exemple dans la Documentation complémentaire du cours le schéma relationnel de la BD INSCRIP. Des informations complémentaires sont données ci-dessous concernant les différentes sections attendues.
Contexte général de la base de données
Cette section présente le contexte global de la base de données. Il faut y être assez précis pour bien comprendre la finalité de la base de données et les éléments contextuels ayant une influence sur cette dernière.
Structure générale de la base de données
Cette section du document présente la schématisation de la modélisation sémantique effectuée pour représenter le contexte de la base de données. En sus du diagramme entités-relations on y retrouve une brève description de chacune des tables. Il est à noter qu'il s'agit ici de la modélisation entités-relations et non de la transformation en tables et en champs de cette dernière. On ne doit ainsi pas y retrouver les clés externes, comme ces dernières proviennent de la transformation des relations.
Structure des tables
Cette section donne toutes les informations nécessaires pour définir les tables dans un SGBD relationnel (type de données, statut obligatoire ou non, clés primaire et/ou externe, index plein texte) ainsi qu'être en mesure de bien comprendre la nature des contenus attendus pour chacun des champs (description des champs et précision, s'il y a lieu, des règles d'écriture). Pour chacune des tables prévues qui proviennent de la transformation de votre diagramme entités-relations, un premier tableau résume les caractéristiques de ses champs :
Nom du champ : Des noms significatifs assez courts sont préférables, exempts de caractères accentués et d'espace.
Type : Il s'agit ici des types génériques de données, les types spécifiques étant définis au moment de l'implantation dans le SGBD. Quatre types sont possibles : Caractère (pour les chaînes de caractères alphanumériques), Numérique (pour des données comportement uniquement des nombres), Date/Heure (pour tous les formats de date et d'heure allant d'une année uniquement jusqu'à la version longue comportant l'heure et la date complète), Logique (pour un champ acceptant seulement deux valeurs comme Vrai ou Faux).
Taille : Cette caractéristique s'applique pour les champs de type Caractère et Numérique. Pour un champ de type Caractère, il s'agit du nombre maximal de caractères attendus pour une entrée. Pour un champ de type Numérique, il s'agit du nombre de chiffres de la valeur maximale attendue. Par exemple, si la valeur maximale attendue est 99, la taille sera de 2. Pour une valeur maximale de 99 999, la taille sera de 5.
Obligatoire : Il s'agit ici de préciser si un champ doit nécessairement comporter une valeur ou s'il peut être laisser vide.
À la suite de ce tableau, il faut indiquer le ou les champs qui serviront de clé primaire pour la table. Si la clé primaire est la combinaison de plusieurs champs, elle est indiquée sous la forme (champ1, champ2). On indique, s'il y a lieu, la ou les clés externes sous la forme CHAMP vers TABLE. Finalement, on précise le ou les index plein texte (s'il y a lieu). Il est en effet utile lors de la modélisation d'identifier les éventuels champs comportant des données textuelles assez denses pour lesquels une recherche plein texte serait utile (en ce cas, un index plein texte est nécessaire).
À la fin du schéma relationnel, un tableau présente la description précise des contenus attendus pour les différents champs en indiquant, lorsque pertinent, les règles d'écriture. La précision est importante comme ces informations guideront les personnes en charge de la saisie. La description des champs est donc un facteur important dans la qualité des données saisies.
Contraintes additionnelles
On retrouve dans cette section toutes les contraintes par rapport aux contenus de la base de données qui n'ont pu être contrôlées par le biais de la définition des champs. Ces contraintes additionnelles pourront, par exemple, être mises en place par programmation.
Exemple de contenus valides
Cette dernière section présente des exemples de contenus valides pour tous les champs de toutes les tables. Il n'est pas nécessaire de mettre beaucoup d'informations; l'important est de donner des exemples des principales règles d'écriture à suivre. Il est toutefois important de bien couvrir les différentes règles d'écriture comme cette section servira d'exemple à la ou les personnes en charge de la saisie.